0. 简介
传统的并发编程模型是基于线程和共享内存的同步访问控制的,共享数据受锁的保护,线程将争夺这些锁以访问数据。通常而言,使用线程安全的数据结构会使得这更加容易。Go的并发原语(goroutine和channel)提供了一种优雅的方式来构建并发模型。Go鼓励在goroutine之间使用channel来传递数据,而不是显式地使用锁来限制对共享数据的访问。
Do not communicate by sharing memory; instead, share memory by communicating.
这就是Go的并发哲学,它依赖CSP(Communicating Sequential Processes)模型,它经常被认为是 Go 在并发编程上成功的关键因素。
本文将介绍Go并发编发编程的的第一个议题:goroutine的实现及其调度原理。
1. 进程、线程和协程
进程,是一段程序的执行过程,是指令、数据及其组织形式的描述,进程是正在执行的程序的实例。进程拥有自己的独立空间。
传统的操作系统中,每个进程有一个地址空间和至少一个控制线程,这几乎可以认为是进程的定义。而这个地址空间中,可以存在多个控制线程的情形,这些线程可以理解为轻量级的进程,除了他们共享地址空间。多线程有以下好处:
- 在许多应用中同时发生着多种活动,其中某些活动会被阻塞,比如I/O操作,而某些程序则需要响应迅速,比如界面请求,因此多线程的程序设计模型会变得更简单;
- 线程比进程更加轻量级,所以其创建、销毁和上下文切换都更快;
- 在多CPU的系统中,多线程可以实现真正的并行。
在操作系统中,进程是操作系统资源分配的单位;线程是处理器调度和执行的基本单位。
Linux中的进程和线程
在Linux中,所有的线程都当做进程来实现,二者的区别在于:进程拥有自己的页表(即地址空间),而线程没有,只能和同一进程内的其他线程共享同一份页表。这个区别的根本原因在于二者调用系统时的传参不同而已。
在Linux2.3.3开始,glibc的fork()函数创建进程时是调用系统调用clone(2)时指定flags为SIGCHLD(共享信号句柄表)。而pthread_create创建线程时,内部也是调用clone函数,其指定的flags如下:
const int clone_flags = (CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SYSVSEM
| CLONE_SIGHAND | CLONE_THREAD
| CLONE_SETTLS | CLONE_PARENT_SETTID
| CLONE_CHILD_CLEARTID
| 0);
clone的函数形式如下:
int clone(int (* fn )(void *), void * stack , int flags , void * arg , ...
/* pid_t * parent_tid , void * tls , pid_t * child_tid */ );
其实Docker底层实现隔离技术,也利用了clone函数这一系统调用。
1.1 线程模型
线程可以分为内核线程和用户线程,用户线程必须依托于内核线程,实现调度,这样就带来了三种线程模型:多对一(M:1)、一对一(1:1)和多对多(M:N)(用户线程对内核线程)。一个用户线程必须绑定一个内核线程才能执行,不过CPU并不知道有用户线程的存在。
1.1.1 多对一用户级线程模型
这种模型是多个用户线程对应一个内核调度线程,所有的线程的创建、销毁和调度都由用户空间的线程库实现,内核不感知这些线程的切换。优点是线程的上下文切换之间不需要陷入内核,速度快。缺点是一旦有一个用户线程有阻塞性的系统调用,比如I/O操作时,系统内核接管后,会阻塞所有的线程。另外,在多处理器的机器上,这种线程模型是没有意义的,无法发挥多核系统的优势。
1.1.2 一对一内核级线程模型
一对一模型中,每个用户线程拥有一个对应的内核调度线程,也就是说,内核会对每个线程进行调度。也因此,线程的创建、销毁和上下文切换,都会陷入到内核态。目前,Linux采用的NPTL(Native POSIX Threads Library)的线程模型就是一对一模型。比如以下例子:
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
void *f(void *arg){
if (!arg) {
printf("arg is NULL\n");
} else {
printf("%s\n", (char *)arg);
}
sleep(100);
return NULL;
}
int main() {
pthread_t p1, p2;
int res;
char *p2String = "I am p2!";
// 创建p1线程
res = pthread_create(&p1, NULL, f, NULL);
if (res != 0) {
printf("创建线程1失败!\n");
return 0;
}
printf("创建线程1\n");
sleep(5);
// 创建p1线程
res = pthread_create(&p2, NULL, f, (void *)p2String);
if (res != 0) {
printf("创建线程2失败!\n");
return 0;
}
printf("创建线程2\n");
sleep(100);
return 0;
}在程序中,我们创建了两个线程,执行如下:
$ gcc thread.c -o thread_c -lpthread
$ ./thread_c
创建线程1
arg is NULL
创建线程2
I am p2!
然后查看进程号和此进程下的线程数。
$ ps -ef | grep thread_c
chenyig+ 5293 5087 0 19:02 pts/0 00:00:00 ./thread_c
chenyig+ 5459 5347 0 19:03 pts/1 00:00:00 grep --color=auto thread_c
$ cat /proc/5293/status | grep Threads
Threads: 3
之所以线程数是3,是因为系统启动进程的时候就自带一个线程,再加上创建的两个线程,所以总数是3,这也证明了Linux的线程模型是1:1的。
1.1.3 多对多两级线程模型
在多对多模型中,结合了1:1模型和M:1模型的优点,避免了他们的缺点。每个用户线程拥有多个内核调度线程,也可以多个用户线程对应一个调度实体。缺点是线程的调度需要内核态和用户态一起实现,导致模型实现十分复杂。NPTL也曾考虑过使用该模型,但是实现太过复杂,需要对内核进行大范围的改动,所以还是采用了1:1模型。现阶段,Go中的协程goroutine就是采用该模型实现的。
package main
import (
"fmt"
"sync"
"time"
)
func f(i int) {
fmt.Printf("I am goroutine %d\n", i)
time.Sleep(100 * time.Second)
}
func main() {
wg := sync.WaitGroup{}
for i := 0; i < 100; i++ {
idx := i
wg.Add(1)
go func() {
defer wg.Done()
f(idx)
}()
}
wg.Wait()
}运行后:
$ go build -o thread_go goroutine.go
$ ./thread_go
I am goroutine 7
I am goroutine 4
I am goroutine 0
I am goroutine 6
I am goroutine 1
I am goroutine 2
I am goroutine 9
I am goroutine 3
I am goroutine 5
I am goroutine 8
然后查看进程号和此进程下的线程数。
$ ps -ef | grep thread_go
chenyig+ 69705 67603 0 17:17 pts/0 00:00:00 ./thread_go
chenyig+ 69735 68420 0 17:17 pts/2 00:00:00 grep --color=auto thread_go
$ cat /proc/69705/status | grep Threads
Threads: 5
可以看到,用户线程(goroutine)和内核线程并不是一一对应的,而是多对多的情形。
2. GMP模型
Go在2012年正式引入GMP模型,然后在1.2版本中引入了协作式的抢占式调度,在1.14版本中实现了基于信号的抢占式调度,并一直沿用至今。
GMP模型中:
- G:取
Goroutine的首字母,即用户态的线程,也叫协程; - M:取
Machine的首字母,和内核线程一一对应,为简单理解,我们可以认为其就是内核线程; - P:取
Processor的首字母,表示处理器(可以理解成用户态的协程调度器),是G和M之间的中间层,负责协程调度。
2.1 G
Goroutine是Go语言调度器中执行的任务实体,其在runtime调度器中的地位与线程在操作系统中的差不多。作为更细粒度的资源调度单元,和线程相比,其占用更小的内存和更低的上下文切换开销。
Goroutine在运行时的结构体是runtime.g,其结构非常复杂,我们挑选一些重要的字段进行介绍。
type g struct {
// Stack parameters.
// stack describes the actual stack memory: [stack.lo, stack.hi).
// stackguard0 is the stack pointer compared in the Go stack growth prologue.
// It is stack.lo+StackGuard normally, but can be StackPreempt to trigger a preemption.
// stackguard1 is the stack pointer compared in the C stack growth prologue.
// It is stack.lo+StackGuard on g0 and gsignal stacks.
// It is ~0 on other goroutine stacks, to trigger a call to morestackc (and crash).
stack stack // offset known to runtime/cgo
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
...
}
以上是和Go运行时栈相关的字段,其中stack结构体如下,只有栈顶和栈底的地址。stackguard0是运行用户协程g的执行栈(go栈)扩张或者收缩的检查的抢占标记。而stackguard1是用于g0和gsignal(这二者后面会介绍)的内核栈(C栈)的扩张或者收缩的检查的抢占标记。
// Stack describes a Go execution stack.
// The bounds of the stack are exactly [lo, hi),
// with no implicit data structures on either side.
type stack struct {
lo uintptr
hi uintptr
}
另外,还有以下三个字段和抢占息息相关。
type g struct {
...
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
preemptStop bool // transition to _Gpreempted on preemption; otherwise, just deschedule
preemptShrink bool // shrink stack at synchronous safe point
...
}
此外,以下字段中,m表示当前协程占用的线程,可能为空。
type g struct {
...
m *m // current m; offset known to arm liblink
sched gobuf
...
}
而sched字段存储了Goroutine调度相关的数据,如下。
type gobuf struct {
// The offsets of sp, pc, and g are known to (hard-coded in) libmach.
//
// ctxt is unusual with respect to GC: it may be a
// heap-allocated funcval, so GC needs to track it, but it
// needs to be set and cleared from assembly, where it's
// difficult to have write barriers. However, ctxt is really a
// saved, live register, and we only ever exchange it between
// the real register and the gobuf. Hence, we treat it as a
// root during stack scanning, which means assembly that saves
// and restores it doesn't need write barriers. It's still
// typed as a pointer so that any other writes from Go get
// write barriers.
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret uintptr
lr uintptr
bp uintptr // for framepointer-enabled architectures
}
其中:
sp:栈顶指针;pc:程序计数器;ctxt:函数闭包的上下文信息,即DX寄存器;bp:栈底指针;
可以看到,goroutine的上下文切换需要保留的寄存器很少,无需保留其他的通用寄存器,至于为啥无需保留,我们留待后续解释。
2.2 M
M表示操作系统的线程,Go语言使用私有结构体runtime.m表示操作系统线程,和runtime.g一样,这个结构体包含了几十个字段,我们也只挑选一些和我们了解其运行机制的介绍。
type m struct {
g0 *g // goroutine with scheduling stack
...
curg *g // current running goroutine
...
}
其中,g0是持有调度栈的goroutine,curg是当前线程上运行的用户goroutine。g0比较特殊,其会深度参与运行时的调度过程,包括goroutine的创建、大内存分配和CGO函数的执行。
另外,在runtime.m中,还有三个与处理器P相关的字段:p、nextp和oldp。另外还是tls字段,通过tls实现m结构体对象与工作线程之间的绑定。
type m struct {
...
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
oldp puintptr // the p that was attached before executing a syscall
...
tls [tlsSlots]uintptr // thread-local storage (for x86 extern register)
...
}
2.3 P
处理器P是线程M和协程G之间的中间层,它能提供线程需要的上下文换环境,也负责调度线程上的等待队列,通过处理器P的调度,每一个内核线程都能执行多个goroutine,且在goroutine陷入系统调用的时候及时让出计算资源,提高线程的利用率。
因为调度器在启动时就会创建GOMAXPROCS个处理器,所以Go语言程序的处理器数量一定会等于GOMAXPROCS,这些处理器会绑定到不同的内核线程上。
type p struct {
...
m muintptr // back-link to associated m (nil if idle)
...
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
...
}
以上,runtime.p表示P的私有结构,m表示其绑定的线程。runq表示其持有的运行goroutine队列,最大256,runnext表示下一个要执行的goroutine。
以上是GMP中协程G、线程M和处理器P的私有结构简介,下面将介绍Go语言调度器的实现。
3. 基础调度过程
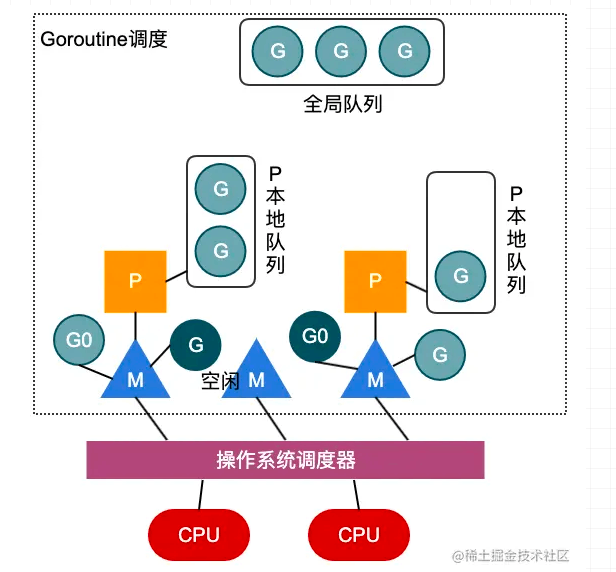
上图简单描述了GMP模型的工作原理,在用户态,处理器P将自身的运行队列中的G交付给线程M执行,通过用户态的调度,实现goroutine之间的调度,每次切换耗费的时间约为~0.2us,低于线程上下文切换的~1us;且每次goroutine的创建,开辟的栈大小为2KB,而线程的创建,都会占用1M以上的内存空间。所以说,无论是在时间上还是空间上,用户态的goroutine的实现都比内核线程的实现要轻量的多。
在图中,深色G表示线程M正在执行的goroutine,而队列中的浅色G则表示等待执行的goroutine队列。而P的个数一般设置为CPU的核数,当然用户可以通过runtime.GOMAXPROCS函数进行设置。而M的个数不一定,当在M上执行的G陷入内核调用而阻塞时,调度器会解绑P和M,优先在空闲M队列中找到一个M进行执行,如果没有空闲M,则创建一个新的M执行剩余队列中的G,充分利用CPU的资源,所以说M的个数不一定。
以上就是Golang并发编程之GMP模型详解的详细内容,更多关于Golang GMP模型的资料请关注好代码网其它相关文章!