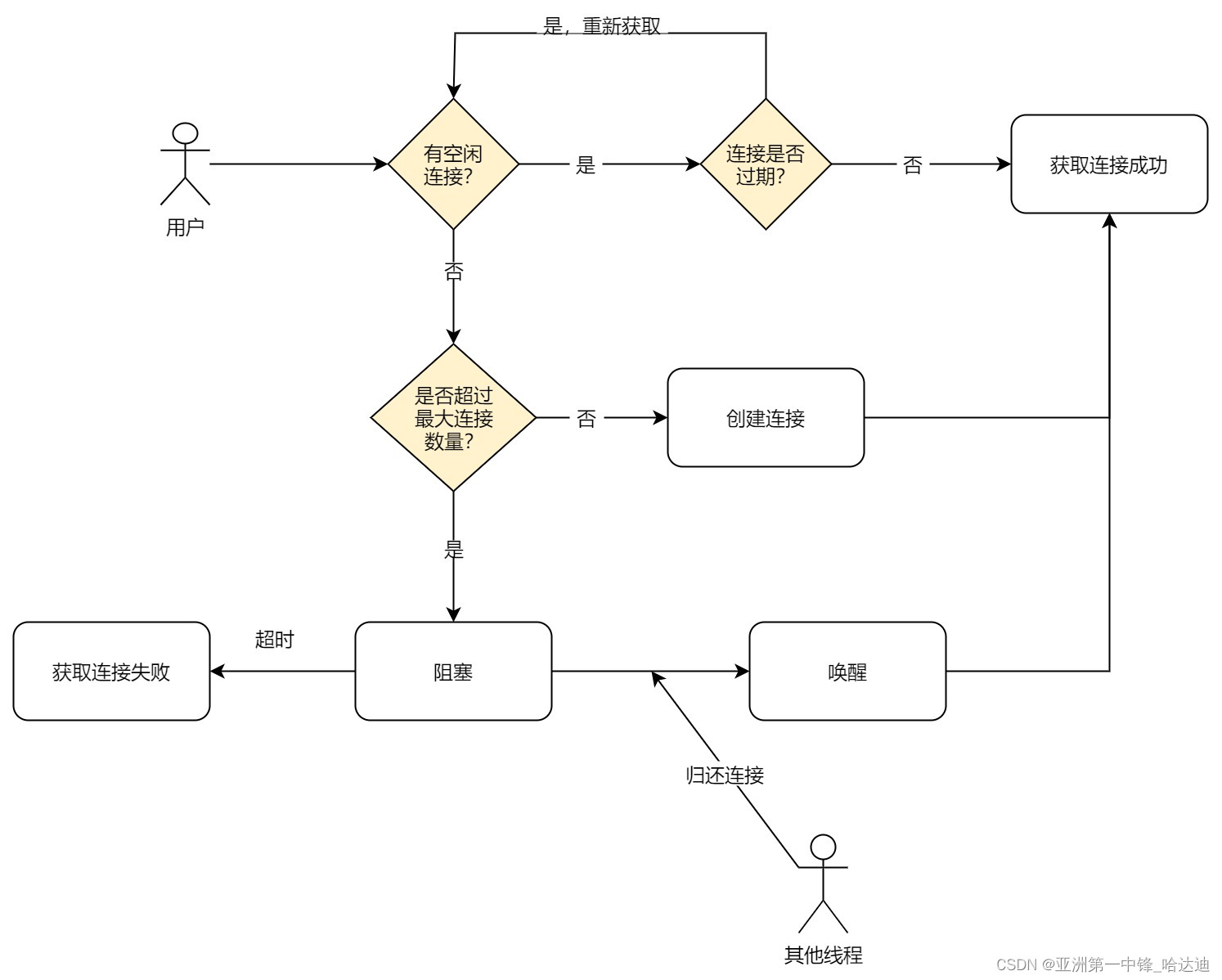
1、哈希表
哈希表用来存储键值对,通过 hash 函数把键值对散列到一个个桶(bucket)中。
Go 使用与运算,桶个数 m,则编号 [0, m-1],把键的 hash 值与 m-1 与运算。为保证所有桶都会被选中,m 一定为 2 的整数次幂。这样 m 的二进制表示一定只有一位为 1,m-1 的二进制表示一定是低于这一位的所有位均为 1。下文扩容规则有详细样例。
- m=4 (00000100)
- m-1 (00000011)
如果桶的个数不是2的整数次幂,就有可能出现有些桶绝对不会被选中的情况 :
- m=5 (00000101)
- m-1 (00000100)
则 [1, 3] 注定是空桶。
负载因子 = count / bucket数量
2、Go map底层实现
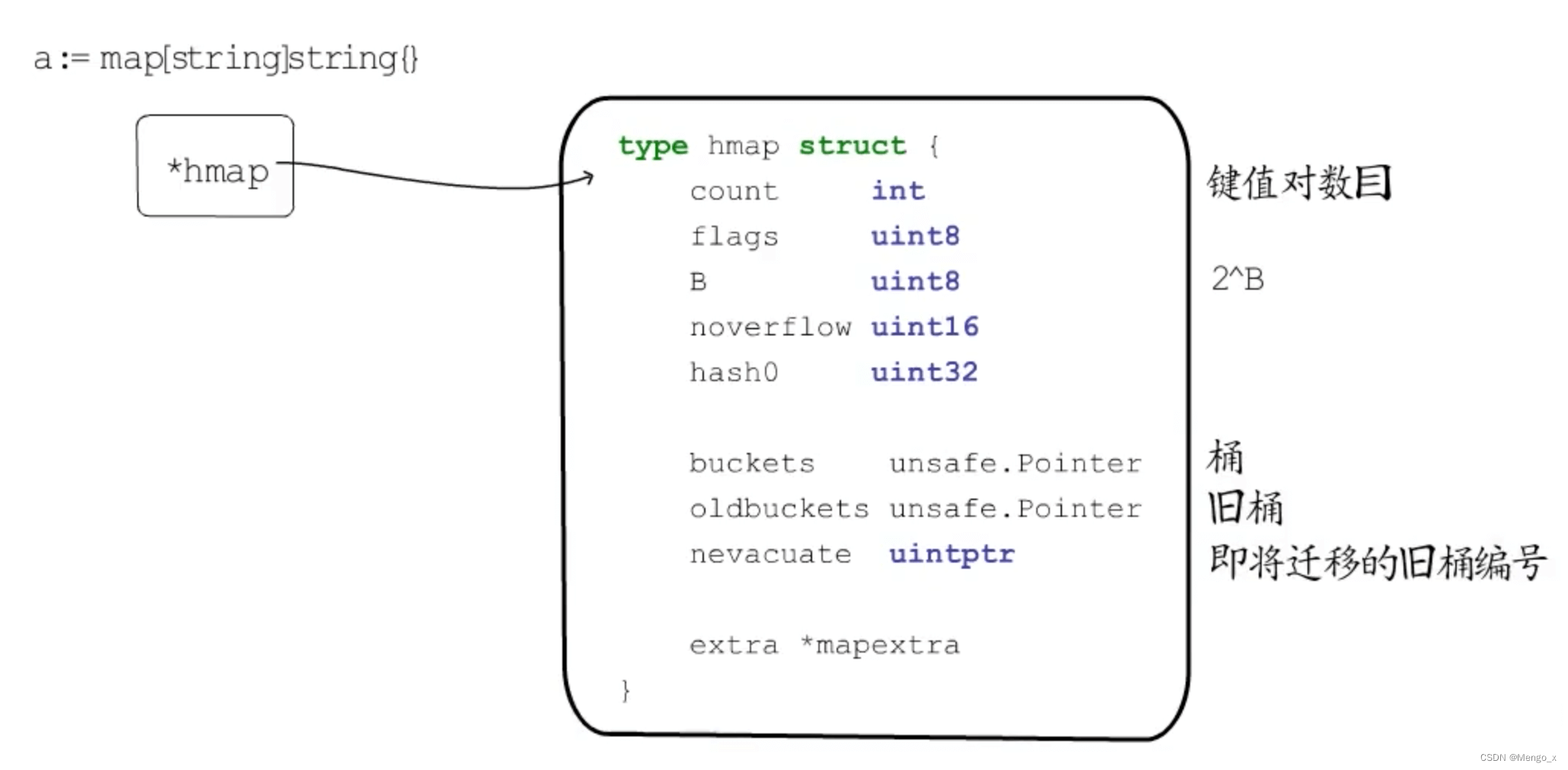
hmap
Golang的map就是使用哈希表作为底层实现,map 实际上就是一个指针,指向hmap结构体。
type hmap struct {
count int // 存储的键值对数目
flags uint8 // 状态标志(是否处于正在写入的状态等)
B uint8 // 桶的数目 2^B
noverflow uint16 // 使用的溢出桶的数量
hash0 uint32 // 生成hash的随机数种子
buckets unsafe.Pointer // bucket数组指针,数组的大小为2^B(桶)
oldbuckets unsafe.Pointer // 扩容阶段用于记录旧桶用到的那些溢出桶的地址
nevacuate uintptr // 记录渐进式扩容阶段下一个要迁移的旧桶编号
extra *mapextra // 指向mapextra结构体里边记录的都是溢出桶相关的信息
}
bmap
buckets 则是指向哈希表节点 bmap 即 bucket 的指针,Go 中一个桶里面会最多装 8 个 key。
hash 值低8位用来定位 bucket,高8位定位 tophash。
type bmap struct {
tophash [bucketCnt]uint8
// len为8的数组,用来快速定位key是否在这个bmap中
// 一个桶最多8个槽位,如果key所在的tophash值在tophash中,则代表该key在这个桶中
}
上面bmap结构是静态结构,在编译过程中runtime.bmap会拓展成以下结构体:
type bmap struct{
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr // 内存对齐使用,可能不需要
overflow uintptr // 当bucket 的8个key 存满了之后
// overflow 指向下一个溢出桶 bmap,
// overflow是uintptr而不是*bmap类型,保证bmap完全不含指针,是为了减少gc,溢出桶存储到extra字段中
}
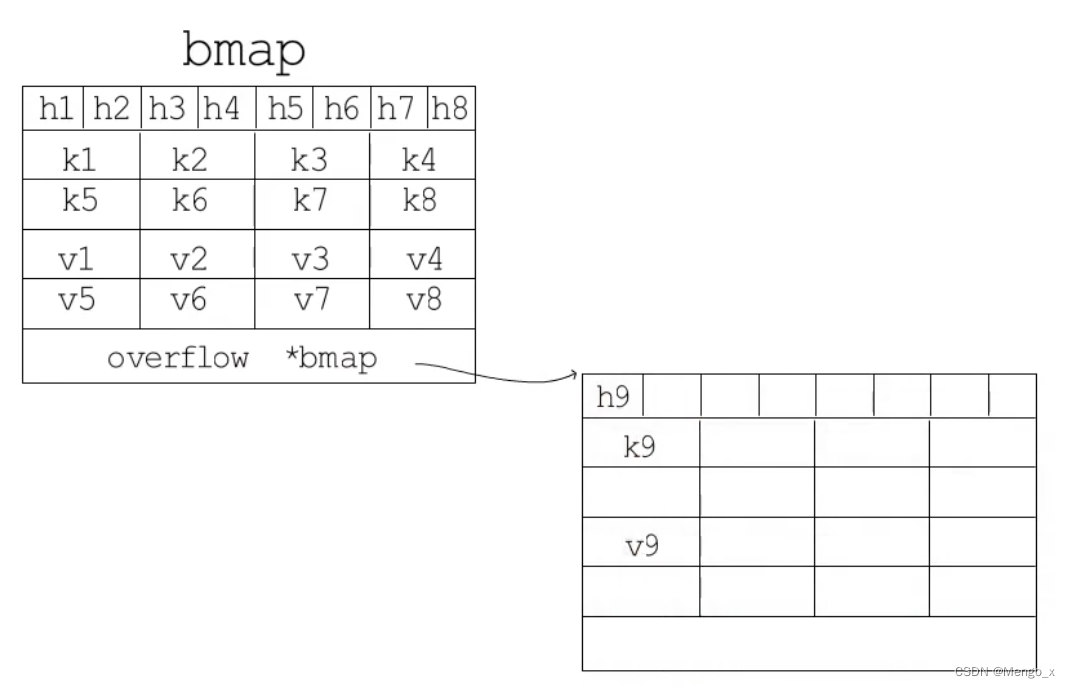
tophash:是个长度为8的数组,哈希值低位相同的键存入当前bucket时会将哈希值的高 8 位存储在该数组中,以方便后续匹配。
tophash字段不仅存储key哈希值的高8位,还会存储一些状态值,用来表明当前桶单元状态,这些状态值都是小于minTopHash的。为了避免key哈希值的高8位值和这些状态值相等,产生混淆情况,所以当key哈希值高8位若小于minTopHash时候,自动将其值加上minTopHash作为该key的tophash。
emptyRest = 0 // 表明此桶单元为空,且更高索引的单元也是空
emptyOne = 1 // 表明此桶单元为空
evacuatedX = 2 // 用于表示扩容迁移到新桶前半段区间
evacuatedY = 3 // 用于表示扩容迁移到新桶后半段区间
evacuatedEmpty = 4 // 用于表示此单元已迁移
minTopHash = 5 // key的tophash值与桶状态值分割线值,小于此值的一定代表着桶单元的状态,大于此值的一定是key对应的tophash值
func tophash(hash uintptr) uint8 {
top := uint8(hash >> (goarch.PtrSize*8 - 8))
if top < minTopHash {
top += minTopHash
}
return top
}
一个桶里边可以放8个键值对,但是为了让内存排列更加紧凑,8个key放一起,8个value放一起,在8个key前面是8个tophash,每个tophash都是对应哈希值的高8位。
当key和value类型不一样的时候,key和value占用字节大小不一样,使用key/value这种形式可能会因为内存对齐导致内存空间浪费。
overflow:指向一个溢出桶,溢出桶的布局与常规的桶布局相同,是为了减少扩容次数引入的(即哈希冲突的拉链法)。当一个桶存满了,还有可用的溢出桶时,就会在桶后边链一个溢出桶继续往里面存。
mapextra与溢出桶
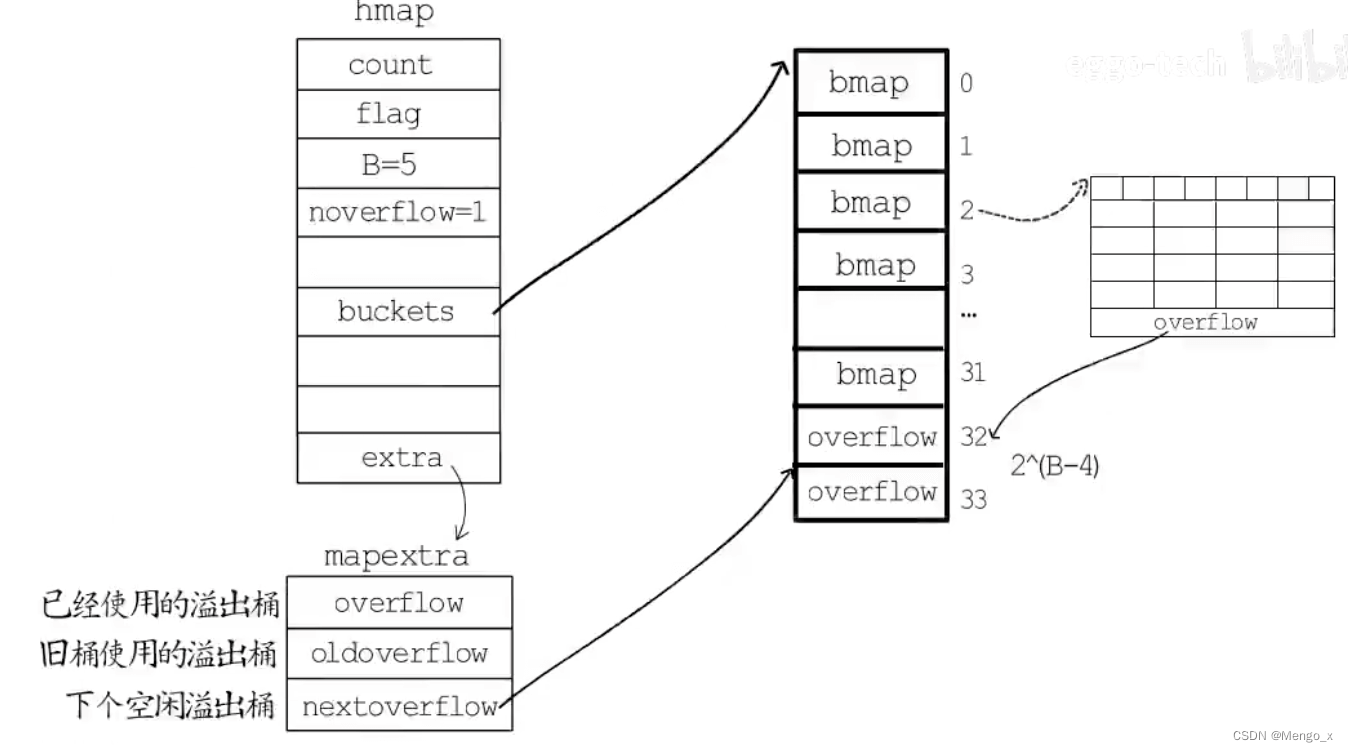
如果哈希表要分配的桶的数目大与 **** 2 4 2^4 24**次方,就认为使用到溢出桶的几率较大,就会预分配 2 ( B − 4 ) 2^{(B-4)} 2(B−4) 个溢出桶备用**,这些溢出桶与常规桶在内存中是连续的,只是前 2 B 2^B 2B 个用作常规桶。
hmap 中最后有 extra 字段,它是指向mapextra结构体,里边记录的都是溢出桶相关的信息。
type mapextra struct {
overflow *[]*bmap // 记录已使用的溢出桶的地址
oldoverflow *[]*bmap // 扩容阶段旧桶使用的溢出桶地址
nextOverflow *bmap // 指向下一个空闲溢出桶地址
}
如下图所示,分配桶数目为 2 5 = 32 2^5 = 32 25=32,则备用溢出桶数目为 2 ( 5 − 4 ) = 2 2^{(5-4)} = 2 2(5−4)=2。
- 此时编号为 2 的
bmap桶存满了,overflow指向下一个溢出桶地址,这里指向 32 号。 hmap中noverflow表示使用溢出桶数量,这里为 1。extra字段指向记录溢出桶的mapextra结构体。mapextra中的nextOverflow指向下一个空闲溢出桶 33 号。
3、扩容规则
map扩容时使用渐进式扩容。
由于 map 扩容需要将原有的 key/value 重新搬迁到新的内存地址,如果map存储了数以亿计的key-value,一次性搬迁将会造成比较大的延时,因此 Go map 的扩容采取了一种称为**“渐进式”的方式,原有的 key 并不会一次性搬迁完毕,每次最多只会搬迁 2 个 bucket。只有在插入或修改、删除 key 的时候,都会尝试进行搬迁 buckets 的工作**。先检查 oldbuckets 是否搬迁完毕,具体来说就是检查 oldbuckets 是否为 nil。
翻倍扩容
count/(2^B) > 6.5:当负载因子超过6.5时就会触发翻倍扩容。
如下图,原来 B = 0,只有一个桶,装满后触发翻倍扩容,B = 1,buckets 指向两个新桶,oldbuckets 指向旧桶,nevacuate 表示接下来要迁移编号为 0 的旧桶。旧桶的键值对会渐进式分流到两个新桶中。直到旧桶中的键值对全部搬迁完毕后,删除oldbuckets。
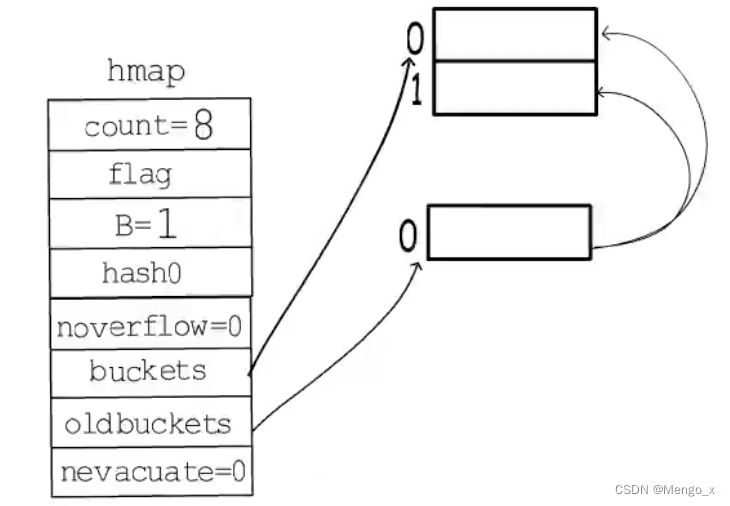
迁移过程中使用与运算法hash & (m-1),把旧桶迁移到新桶上,用这个旧桶的hash值跟扩容后的桶的个数 m-1 的值相与(&),得几就在哪个位置上。
如果旧桶数量为4,那么新桶的数量就为 8。如果一个哈希值选择 0 号旧桶,那么哈希值的二进制低两位一定为 0。
旧桶 m-1 = 3 = 00000011,选择 0 号旧桶说明哈希值为 xxxxxx00,00000011 & xxxxxx00 = 0
所以选择新桶的结果只有两种,取决于哈希值的第三位是 0还是 1。
新桶 m-1 = 7 = 00000111,与原哈希值与运算,若第三位是 0 则为 0,第三位为 1 则为 00000100 = 4。
等量扩容
虽然没有超过负载因子限制,但是使用溢出桶过多,就会触发等量扩容,创建和旧桶数目一样多的新桶,然后把原来的键值对迁移到新桶中。
如果常规桶的数目小于等于 2 15 2^{15} 215 , 使用的溢出桶大于常规桶数目 2 B 2^B 2B就是多了。
B <= 15,noverflow >= 2^B
如果常规桶的数目大于 2 15 2^{15} 215 , 使用的溢出桶大于 2 15 2^{15} 215就是多了。
B > 15, noverflow >= 2^15
一般发生在很多键值对被删除的情况下,这样会造成overflow的bucket数量增多,但负载因子又不高。同样数目的键值对,迁移到新桶中会把松散的键值对重新排列一次,使其排列的更加紧凑,进而保证更快的存取,这就是等量扩容的意义所在。
4、其他特性
map遍历无序
使用 range 多次遍历 map 时输出的 key 和 value 的顺序可能不同。这是 Go 语言的设计者们有意为之,旨在提示开发者们,Go 底层实现并不保证 map 遍历顺序稳定,请大家不要依赖 range 遍历结果顺序。
主要原因有2点:
- map在遍历时,并不是从固定的0号bucket开始遍历的,每次遍历,都会从一个随机值序号的bucket,再从其中随机的cell开始遍历
- map遍历时,是按序遍历bucket,同时按需遍历bucket中和其overflow bucket中的cell。但是map在扩容后,会发生key的搬迁,这造成原来落在一个bucket中的key,搬迁后,有可能会落到其他bucket中了,从这个角度看,遍历map的结果就不可能是按照原来的顺序了
map 本身是无序的,且遍历时顺序还会被随机化,如果想顺序遍历 map,需要对 map key 先排序,再按照 key 的顺序遍历 map。
map非线程安全
Go 官方认为 Go map 更应适配典型使用场景(不需要从多个 goroutine 中进行安全访问),而不是为了小部分情况(并发访问),导致大部分程序付出加锁代价(性能),决定了不支持,若并发读写 map 直接报错。
官方推荐对 map 上读写锁,一个匿名结构(struct)体,包含一个原生和一个嵌入读写锁 sync.RWMutex:
var counter = struct{
sync.RWMutex
m map[string]int
}{m: make(map[string]int)}
counter.RLock()
n := counter.m["煎鱼"]
counter.RUnlock()
counter.Lock()
counter.m["煎鱼"]++
counter.Unlock()
map 的数据量非常大时,只有一把锁会效率低下,分区见上锁又逻辑复杂。Go1.9 起支持的 sync.Map,其支持并发读写 map。采取了 “空间换时间” 的机制,冗余了两个数据结构,分别是:read 和 dirty,减少加锁对性能的影响。
type Map struct {
mu Mutex
read atomic.Value // readOnly
dirty map[interface{}]*entry
misses int
}
其是专门为 append-only 场景设计的,也就是适合读多写少的场景。如果写多性能会急剧下降。
到此这篇关于Go map底层实现与扩容规则和特性分类详细讲解的文章就介绍到这了,更多相关Go map底层实现内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!