一、简介
高可用(HA)是系统架构设计中必须考虑的,是指系统所能提供无故障服务的一种能力。即避免因为服务器宕机导致的服务不可用的情况。
二、衡量
可用性 = 平均故障间隔/(平均故障间隔 + 故障恢复平均时间)
三、如何设计高可用
想要高可用就要避免使用单点,你想想看你的单台服务器再强应用优化的再极致,只要它宕机,就啥都凉凉了,所以需要多台机器也就是需要集群,方法论中叫冗余。只是有了集群是不能完全满足复杂业务的高可用的,我们要让系统在当前节点宕机的情况下,自己进行切换到好的节点去,这即所谓的故障转移。所以我们现在设计高可用系统的目标明确了。关键字:冗余、故障转移
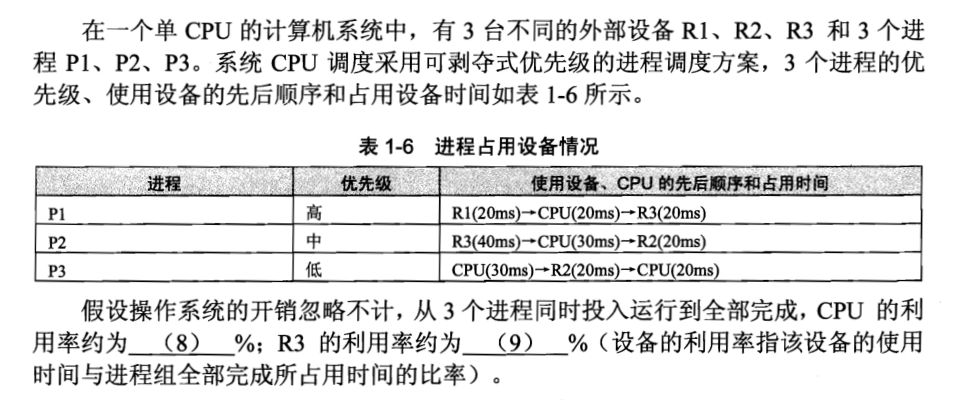
大部分互联网公司的系统架构:

2.1、上图会出现的问题和解决办法
1、 从客户端到反向代理Nginx这块,这个1台nginx是会可能发生故障的,所以这里可以再冗余一台Nginx,可以利用linux的 keeplived进行探测可用性,当一台Nginx挂了之后,则会自动转移到另一台Nginx机器上来,从而保证高可用。
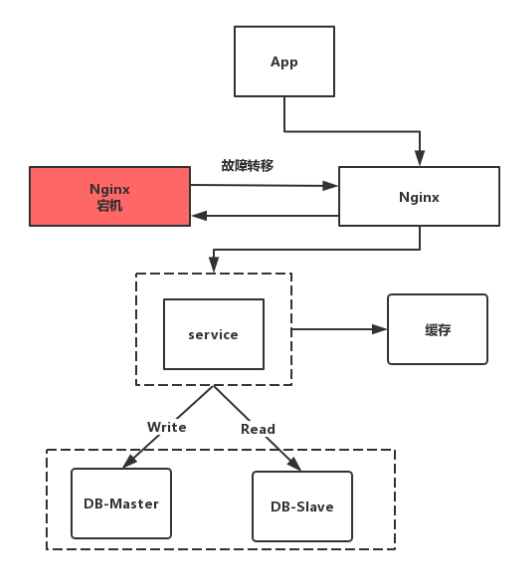
2、从反向代理到后端服务service这块,反向代理这块,目前最受欢迎的是nginx,性能方面表现也很好,nginx能够自动探测后端服务的可用性,只需在nginx,config配置多台后端服务就行了。

3、后端服务到缓存这块,缓存这块推荐使用redis主从同步方案来达到高可用,redis主从同步加上sentine哨兵机制来自动探活redis实例。

4、从后端服务到写数据库这块,这里可以采用双主机制,一台给线上使用,另一台冗余,当线上那台挂了才会阶梯过来使用写功能,同样是通过linux的keepalived进行自动探活。
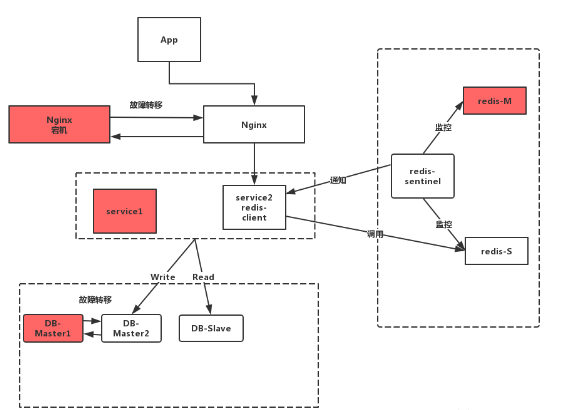
5、从后端服务到读数据库这块,这里同样是将读库部署多台,例如部署2台,通过代码段增加连接池组件进行路由读库和探活。
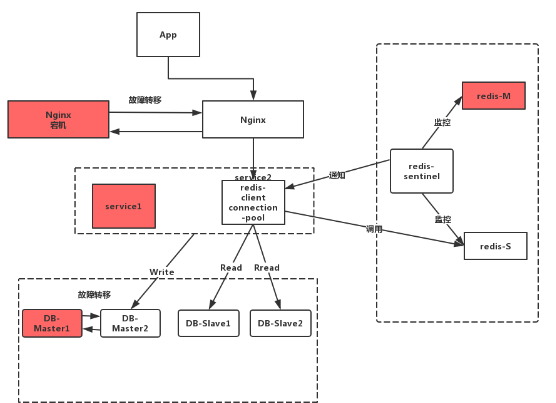
四、延伸思路
在编码的时候除了故障转移方案,同样需要考虑很多东西来保证系统的可用性,主要想体现在,超时机制、降级、限流等。
4.1、超时
系统调用三方接口,而这个三方接口一般是合作公司的或者是公司其他部门提供的,我们并不清楚对方接口的性能情况,有些接口在并发稍大一点的情况下会出现返回很慢,一直占用当前资源,使得我们大量的请求阻塞等。所以这块我们需要对此进行设置合理的超时时间,来快速结束这些慢请求,来保证我们系统的可用性。
有个业务发生过类似的事件,对方接口在我们一定并发的时候经常很慢很慢才会出现结果,最后造成我们OOM(Out Of Memory 内存耗尽),最终发现是这个业务程序员没有合理设置超时时间造成的。
超时时间如何设置,需要根据自己的业务以及接口情况加上多次分析线上时间,来合理设置,可以不停的对其设置直到业务愉快的进行。
4.2、降级
降级也是互联网中老生常谈的话题,那么我们使用降级方案如何来保证系统的可用性呢,分析自己的业务,在面对流量剧增的时候,例如,秒杀,大促等这些剧增的大流量,可以将不影响本次业务的流程也砍掉,不去调用了,直接走核心业务。其实各大电商都是采取这种方案来保证系统的可用性的。
4.3、限流
本来系统只能抗住10万并发,然后现在我运营搞了什么牛逼的大促,搞的来了10倍的流量,那么系统就把瞬间不能处理的流量给截断,直接返回给用户,用户可以待会儿再试。所以限流就是为了保证系统的高可用而限制住大流量的情况发生。