问题描述
项目中使用的服务器是物理机,使用 centos 7.6 版本的操作系统, 4 个千兆网口,上架时间 23 年 8 月份。部署在内网机房,并且在内网机房分配的固定IP 是 172.87.7.249,并在机器上部署了 docker,
大概在 10 月中旬左右,这台机器出现访问时好是坏的问题;前期出现时一直以为是机房调整网络环境导致,短暂性的不可访问没有实际影响业务,所以就没太关注。但是从 10 月底开始,机器开始频繁性出现不可访问的问题,开始接入排查。
同机房同机柜还有其他 3 台服务器,ip 地址分别为 172.87.7.246,172.87.7.247,172.87.7.248。在 172.87.7.249 出现频繁性不可访问的同时,在办公网环境其他 3 台机器访问均无影响,并在当在办公网通过 ssh 登录 172.87.7.249 提示 Connection refused 时,通过其他三台机器的任何一台 ssh 登录 172.87.7.249,却可以登录。
总结下现象:
- 1、
172.87.7.246,172.87.7.247,172.87.7.248,172.87.7.249同处一个机房,一个机柜,连接的也是同一个核心交换机,同一个网关。 - 2、办公网环境访问
172.87.7.249,前期偶发性时好时坏,后期频繁不可访问,间歇性可访问。 - 3、办公网环境访问
172.87.7.248/247/246,正常。 - 4、
172.87.7.248/247/246访问172.87.7.249前期正常,后期短暂间歇性不可访问,但大多数情况下是可以访问的。 - 5、
172.87.7.249能 ping 通
看到这里,对于熟悉网络的大神应该能猜到个八九不离十的原因了,但是对于研发工程师来说,网络问题一直都是技术上的疼点。
下面就从研发视角来看下排查过程。
排查过程
防火墙配置
一般情况下,IP 能 ping 通,端口无法访问,99% 的原因都是出在防火墙;
- 1、先通过
systemctl status firewalld查看防火墙状态,可以看到防火墙正常开启
[root@localhost ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active: active (running) since 二 2023-11-21 00:29:44 CST; 3 days ago
Docs: man:firewalld(1)
Main PID: 63661 (firewalld)
Tasks: 2
Memory: 26.0M
CGroup: /system.slice/firewalld.service
└─63661 /usr/bin/python2 -Es /usr/sbin/firewalld --nofork --nopid
11月 21 00:29:44 172-87-7-249.brainerd.net systemd[1]: Starting firewalld - dynamic firewall daemon...
11月 21 00:29:44 172-87-7-249.brainerd.net systemd[1]: Started firewalld - dynamic firewall daemon.
- 2、通过
firewall-cmd --list-ports查看端口开发策略,22 端口正常的
[root@localhost ~]# firewall-cmd --list-ports 22/tcp 80/tcp 9080/tcp
一般情况下,默认 zone 是 public;
- 3、这里为了避免可能是 zone 策略问题,也看了下 zone 和出网网卡的对应
[root@localhost ~]# firewall-cmd --get-active-zones public interfaces: enp61s0f0 [root@localhost ~]# [root@localhost ~]# firewall-cmd --get-zone-of-interface=enp61s0f0 public [root@localhost ~]#
这里也没问题,同时为了避免环境差异,对比了其他三台机器,配置策略都是一样的。
进程是否 OK
之前在使用 onlyoffic 时遇到的一个问题,在宿主机上通过 docker 启动 onlyoffic,启动完成之后通过 docker ps 查看镜像运行状态是正常的,通过 netstat 查看端口对应的进程也存在(宿主机的),但是也是端口无法访问;当时问题是因为镜像容器内部的 nginx 进程没有被拉起导致的,就是宿主机的端口正常,但是映射到容器内部的端口对应的进程不存在。
为了避免重复踩坑,也涨了记性查了下进程
[root@localhost ~]# ps -ef | grep sshd root 93164 171028 0 14:02 ? 00:00:00 sshd: root@pts/0 root 96871 93211 0 14:18 pts/0 00:00:00 grep --color=auto sshd root 171028 1 0 11月13 ? 00:00:00 /usr/sbin/sshd -D
sshd 进程也是正常的。实际上到这里从研发视角的排查基本就到头了,但是这些都是正常的,问题依然存在。
是否和 docker 有关
在排查完防火墙和进程之后,把目标瞄向了 docker 容器了,这里的依据是:
- 1、执行
systemctl status firewalld时,有一条告警
WARNING: COMMAND_FAILED: '/usr/sbin/iptables -w10 -D FORWARD -i docker0 -o d
- 2、执行
firewall-cmd --get-zones时,提示
block dmz docker drop external home internal nm-shared public trusted work
实际上这两个问题从排查来看,并不是前述问题的原因,但是这两个提示把我们排查的方向带的有点偏。首先是第一个告警,这个问题是因为 dockerd 启动时,参数 –iptables 默认为 true,表示允许修改 iptables 路由表;当时排查时,我是直接将 docker stop 掉了,因此排除了这个因素,如果需要修改docker iptables ,可以在 /etc/docker/daemon.json 这个文件修改。
关于第二个,这里稍微介绍下;firewalled 有两个基础概念,分别是 zone 和 service,每个 zone 里面有不同的 iptables 规则,默认一共有 9 个 zone,而 Centos7 默认的 zone 为 public:
drop(丢弃):任何接收的网络数据包都被抛弃,没有任何回复。仅能有发送出去的网络连接。block(限制):任何接收的网络连接都被IPv4的icmp-host-prohibited信息和IPv6的icmp-adm-prohibited信息所拒绝。public(公共):在公共区域使用,不能相信网络内的其他计算机不会对你的计算机造成危害,只能接收经过选取的连接external(外部):特别是为路由器启用了伪装功能的外部网。你不能信任来自网络的其他计算,不能相信它们不会对你的计算机造成危害,只能接收经过选择的连接。dmz(非军事区):用于你的非军事区内的计算机,此区域内可公开访问,可以有限地进入你的内部网络,仅仅接收经过选择的连接。work(工作):用于工作区。你可以基本相信网络内的其它计算机不会危害你的计算机。仅仅接收经过选择的连接。home(家庭):用于家庭网络。你可以基本信任网络内的其它计算机不会危害你的计算机。仅仅接收经过选择的连接。internal(内部):用于内部网络。你可以基本上信任网络内的其它计算机不会威胁你的计算机,仅仅接收经过选择的连接。trusted(信任):可接收所有的网络连接docker: 这个当我们在机器上启动 dockerd 时,docker 自己会默认创建一个 zone。
根据前面防火墙部分的排查,我们的规则是在 public zone 的,是正常的。
IP 冲突
在排查完上面几种情况之后,已经开始怀疑是不是硬件问题导致的。并且联系和厂商和机房网管从机房防火墙层面开始排查,但是结论都是正常。这个问题和两位小伙伴闲聊提了下,他们猜测的点中包括了上面的几种情况,此外还提到一个点就是可能是 IP 冲突。
实际上一开始关于 IP 冲突,第一直觉就是不大可能,因为机房里面的机器都是固定分配的,而且不同单位分配的地址也是按段分配,所以不大可能出现 IP 冲突。DHCP
但是在排除上述可以排查的所有问题之后,我又把排查思路转义回到了这个问题上,并开始测试。这里使用的工具是 arp-scan。
执行:sudo arp-scan -I eno1 -l (eno1 是我使用的测试机器的网卡标识)
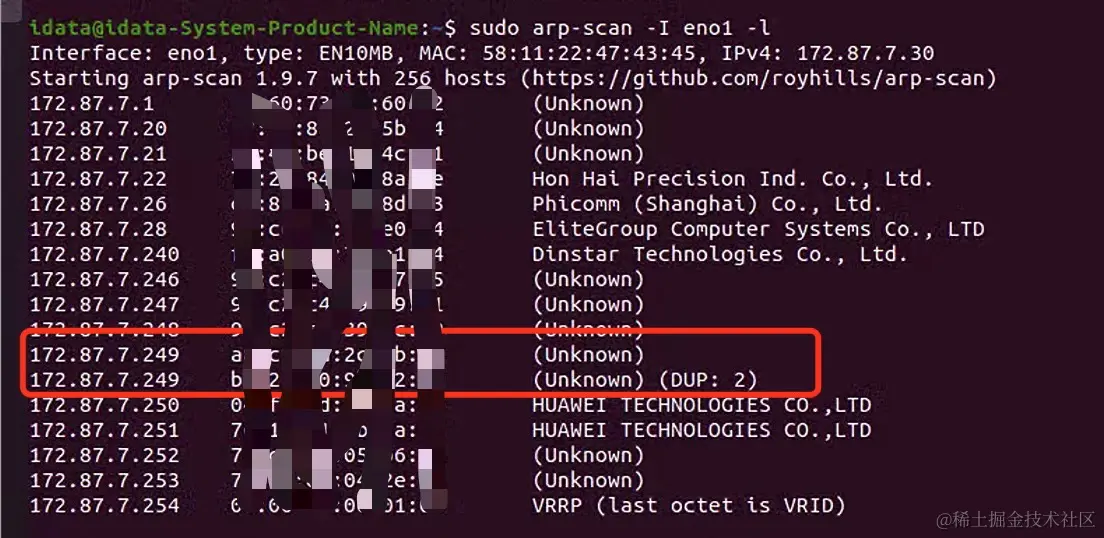
可以看到,确实存在两个相同的 IP,并且有一台通过 mac 地址对比是我们的机器。通过 arping 也可以看到能够收到两台设备返回的数据包。

那至此基本是明确是因为 IP 冲突导致的。一开始因为当前 IP 绑定了一些上下游服务,不大想改我们的 ip,于是就尝试从 mac 地址来找设备,但是没能实现。如果你的环境允许,你可以先是通过https://mac.bmcx.com/ 查了下当前冲突的那个 mac 地址对应的设备类型和厂商来缩小人工排查范围。
最后再回头来盘一下 IP 冲突的问题,因为之前提到,机房内的设备 IP 都是固定分配的,那为什么会存在 IP 冲突呢?这只能是我们当前环境是如此的糟糕,当找网管要了办公区及机房 IP 段分配标准时发现,机房的 IP 和办公区域的 IP 分段规则是有重合的。比如机房的 172.87.7.xxx 在办公网环境也会存在,并且是基于 DHCP 协议自动分配 IP 的。
总结
本篇主要记录了一次 Linux 服务端口访问不通问题的排查过程,涉及到了 Linux 防火墙、进程/端口、Docker 以及 arp-scan 等方向和工具。事实证明,大多数问题并不是那么复杂,在没有足够的知识积累的情况下,总归是要花这些成本去弥补自己知识欠缺的。最后想说的就是,一个耗费相当大精力排查的问题,不一定是复杂的问题,往往这个问题的产生原因是相关简单的。
以上就是Linux服务器端口不可访问问题的排查及解决方法的详细内容,更多关于Linux服务器端口不可访问的资料请关注好代码网其它相关文章!