SELECT * from table where username like '%陈哈哈%' and hobby like '%牛逼'
这是一条我们在MySQL中常用到的模糊查询方法,通过通配符%来进行匹配,其实,这只是冰山一角,在MySQL中,支持模糊匹配的方法有很多,且各有各的优点。好了,今天让我带大家一起掀起MySQL的小裙子,看一看模糊查询下面还藏着多少鲜为人知的好东西。
一、MySQL通配符模糊查询(%,_)
1-1. 通配符的分类
- "%" 百分号通配符: 表示任何字符出现任意次数 (可以是0次)。
- "_" 下划线通配符:表示只能匹配单个字符,不能多也不能少,就是一个字符。当然,也可以like "陈____",数量不限。
- like操作符:LIKE作用是指示mysql后面的搜索模式是利用通配符而不是直接相等匹配进行比较;但如果like后面没出现通配符,则在SQL执行优化时将 like 默认为 “=”执行
注意: 如果在使用like操作符时,后面没有使用通用匹配符(%或_),那么效果是和“=”一致的。在SQL执行优化时查询优化器将 like 默认为 “=”执行,SELECT * FROM movies WHERE movie_name like '唐伯虎';只能匹配movie_name=“唐伯虎”的结果,而不能匹配像“唐伯虎点秋香”或“唐伯虎点香烟”这样的结果.
1-2. 通配符的使用
1) % 通配符:
-- 模糊匹配含有“网”字的数据
SELECT * from app_info where appName like '%网%';
-- 模糊匹配以“网”字结尾的数据
SELECT * from app_info where appName like '%网';
-- 模糊匹配以“网”字开头的数据
SELECT * from app_info where appName like '网%';

-- 精准匹配,appName like '网' 等同于:appName = '网'
SELECT * from app_info where appName = '网'; -- 等同于 SELECT * from app_info where appName like '网';
-- 模糊匹配含有“xxx网xxx车xxx”的数据,如:"途途网约车司机端、网络约车平台"
SELECT * from app_info where appName like '%网%车%';
2) _ 通配符:
-- 查询以“网”为结尾的,长度为三个字的数据,如:"链家网",
SELECT * from app_info where appName like '__网';
注意:'%__网、__%网' 等同于 '%网'
-- 查询前三个字符为XX网,后面任意匹配,如:"城通网盘、模具网平台"
SELECT * from app_info where appName like '__网%';
-- 模糊匹配含有“xx网x车xxx”的数据,如:"携程网约车客户端"
SELECT * from app_info where appName like '__网_车%';
注意事项:
注意大小写,在使用模糊匹配时,也就是匹配文本时,MySQL默认配置是不区分大小写的。当你使用别人的MySQL数据库时,要注意是否区分大小写,是否区分大小写取决于用户对MySQL的配置方式.如果是区分大小写,那么像Test12这样记录是不能被"test__"这样的匹配条件匹配的。
注意尾部空格,"%test"是不能匹配"test "这样的记录的。
注意NULL,%通配符可以匹配任意字符,但是不能匹配NULL,也就是说SELECT * FROM blog where title_name like '%';是匹配不到title_name为NULL的的记录。
1-3. 技巧与建议:
正如所见,MySQL的通配符很有用。但这种功能是有代价的:通配符搜索的处理一般要比前面讨论的其他搜索所花时间更长,消耗更多的内存等资源。这里给出一些使用通配符要记住的技巧。
- 不要过度使用通配符。如果其他操作符能达到相同的目的,应该使用其他操作符。
- 在确实需要使用通配符时,除非绝对有必要,否则不要把它们用在搜索模式的开始处。因为MySQL在where后面的执行顺序是从左往右执行的,如果把通配符置于搜索模式的开始处(最左侧),搜索起来是最慢的(因为要对全库进行扫描)。
- 仔细注意通配符的位置。如果放错地方,可能不会返回想要的数据。
有细心地朋友会发现,如果数据中有“%”、“_”等符号,那岂不是和通配符冲突了?
SELECT * from app_info where appName LIKE '%%%'; SELECT * from app_info where appName LIKE '%_%';
确实如此,上面面两条SQL语句查询的都是全表数据,而不是带有"%"和"_"的指定数据。这里需要加 ESCAPE 关键字进行转义。
如下,ESCAPE 后面跟着一个字符,里面写着什么,MySQL就把那个符号当做转义符,一般我就写成"/";然后就像 C语言中转义字符一样 例如 ‘\n','\t', 把这个字符写在你需要转义的那个%号前就可以了;
SELECT * from app_info where appName LIKE '%/_%' ESCAPE '/';

但是这种情况有没有更高端点的解决办法呢?能让检查你代码的同事或领导对你刮目相看那种~~
当然,下面我们就来看看MySQL的第二类模糊匹配方式 --- 内置函数查询
二、MySQL内置函数检索(locate,position,instr)
话接上文,通过内置函数locate,position,instr进行匹配,相当于Java中的str.contains()方法,返回的是匹配内容在字符串中的位置,效率和可用性上都优于通配符匹配。
SELECT * from app_info where INSTR(`appName`, '%') > 0;
SELECT * from app_info where LOCATE('%', `appName`) > 0;
SELECT * from app_info where POSITION( '%' IN `appName`) > 0;
如上,三种内置函数默认都是:> 0,所以下列 > 0 可加可不加,加上可读性更好。
OK,下面一起来看看这三种内置函数的使用方法吧。
先明确一下,MySQL中的角标从左往右是从1开始的,不像java最左边第一位角标是0,因此在MySQL中角标为0时说明不存在。
2-1. LOCATE()函数
语法: LOCATE(substr,str)
返回 substr 在 str 中第一次出现的位置。如果 substr 在 str 中不存在,返回值为 0,如果substr 在 str 中存在,返回值为:substr 在 str中第一次出现的位置。
注意:LOCATE(substr,str)与 POSITION(substr IN str)是同义词,功能相同。
语法: LOCATE(substr, str, [pos])
从位置pos开始的字符串str中第一次出现子字符串substr的位置。 如果substr不在str中,则返回0。 如果substr或str为NULL,则返回NULL。
SELECT locate('a', 'banana'); -- 2
SELECT locate('a', 'banana', 3); -- 4
SELECT locate('z', 'banana'); -- 0
SELECT locate(10, 'banana'); -- 0
SELECT locate(NULL , 'banana'); -- null
SELECT locate('a' , NULL ); -- null
实例:
-- 用LOCATE关键字进行模糊匹配,等同于:"like '%网%'"
SELECT * from app_info where LOCATE('网', `appName`) > 0;
-- 用LOCATE关键字进行模糊匹配, 从第二个字符开始匹配"网",则"网易云游戏、网来商家"等数据就被过滤了
SELECT * from app_info where LOCATE('网', `appName`, 2) > 0;
2-2. POSITION()方法
语法:POSITION(substr IN substr)
这个方法可以理解为locate(substr,str)方法的别名,因为它和locate(substr,str)方法的作用是一样的。
实例:
-- 用POSITION关键字进行模糊匹配,等同于:"like '%网%'"
SELECT * from app_info where POSITION( '网' IN `appName`);
2-3. INSTR()方法
语法: INSTR(str,substr)
返回字符串str中第一次出现子字符串substr的位置。INSTR()与LOCATE()的双参数形式相同,只是参数的顺序相反。
实例:
-- 用INSTR关键字进行模糊匹配,功能跟like一样 ,等同于:"like '%网%'"
SELECT * from app_info where INSTR(`appName`, '网');
-- instr函数作用,一般用于检索某字符在某字符串中的位置,等同于:"like '%网%'"
SELECT * from app_info where INSTR(`appName`, '网') > 0;
三、MySQL基于regexp、rlike的正则匹配查询
MySQL中的regexp和rlike关键字属于同义词,功能相同。本文以regexp为准。
REGEXP 不支持通配符"%、_",支持正则匹配规则,是一种更细力度且优雅的匹配方式,一起来看看吧
-- 这里给出regexp包含的参数类型
| 参数类型 | 作用 |
| (^) | 匹配字符串的开始位置,如“^a”表示以字母a开头的字符串。 |
| ($) | 匹配字符串的结束位置,如“X^”表示以字母X结尾的字符串。 |
| (.) | 这个字符就是英文下的点,它匹配任何一个字符,包括回车、换行等。 |
| (*) | 星号匹配0个或多个字符,在它之前必须有内容。如:select * from table where name regexp 'ba*'(可以命中“baaa”) |
| (+) |
加号匹配1个或多个字符,在它之前也必须有内容。加号跟星号的用法类似,只是星号允许出现0次,加号则必须至少出现一次。 |
| (?) | 问号匹配0次或1次。 |
| {n} | 匹配指定n个 |
| {n,} | 匹配不少于n个 |
| {n,m} | 匹配n-m个 |
-- REGEXP '网' 等同于 like '%网%'
SELECT * from app_info where appName REGEXP '网'; -- 等同于 SELECT * from app_info where appName like '%网%';
3-1. regexp中的 OR : |
功能:可以搜索多个字符串之一,相当于 or
-- 支持 "|" ‘或'符号,匹配包含“中国”或“互联网”或“大学”的数据,支持叠加多个
SELECT * from app_info where appName REGEXP '中国|互联网|大学';
-- 匹配同时命中“中国”、“网”的数据可以用".+"连接,代表中国xxxx网,中间允许有任意个字符,顺序不能反。
SELECT * from app_info where appName REGEXP '中国.+网';
3-2. REGEXP中的正则匹配 : []
功能:匹配[]符号中几个字符之一,支持解析正则表达式
-- 匹配包含英文字符的数据,默认不区分大小写情况下
SELECT * from app_info where appName REGEXP '[a-z]';
-- 跟like一样,取反集加 "not REGEXP" 即可,下面不再赘述
SELECT * from app_info where appName not REGEXP '[a-z]';
-- 匹配包含大写英文字符的数据,默认忽略大小写,需要加上"BINARY"关键字。如where appName REGEXP BINARY 'Hello'
-- 关于大小写的区分:MySQL中正则表达式匹配(从版本3.23.4后)不区分大小写 。
SELECT * from app_info where appName REGEXP BINARY '[A-Z]';

-- 匹配包含数字的数据
SELECT * from app_info where appName REGEXP '[0-9]';
-- 匹配包含数字或英文的数据,
SELECT * from app_info where appName REGEXP '[a-z0-9]';
a-z、0-9都认定为一个单位,不要加多余符号,前两天就发现了一个特殊情况,很有意思的bug,跟他家分享一下
-- 之前写查询语句时多加了"|"符号,以为是"或",没有在意,但万万没想到,查出数量竟不同
SELECT * from app_info where appName REGEXP '[567]'; -- 87条 SELECT * from app_info where appName REGEXP '[5|6|7]'; -- 88条
一头雾水,赶快看看差得是哪一条
-- 原来"|"符号也参与到了匹配中,认定为一个单位。巧的是有一个数据为:“无线调音台 | Wireless Mixer” 这个正好匹配上。卧槽了个DJ
SELECT * from app_info where appName REGEXP '[5|6|7]' and pid not in (SELECT pid from app_info where appName REGEXP '[567]');

-- 查询以5、6、7其中一个为开头的数据
SELECT * from app_info where appName REGEXP '^[5|6|7]';
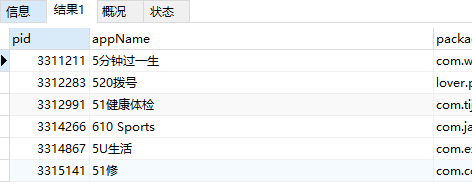
-- 查询以5、6、7其中一个为结尾的数据
SELECT * from app_info where appName REGEXP '[5|6|7]$';
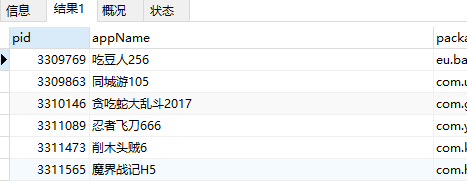
温馨提示:MySQL中,UTF-8的中文=3个字节;GBK的中文=2个字节
-- 查询appName字节长度为10,任意内容的数据
SELECT * from app_info where appName REGEXP '^.{10}$';
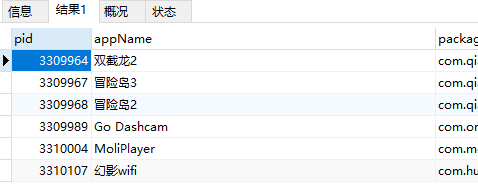
-- 查询appName字节长度为10,且都为英文的数据
SELECT * from app_info where appName REGEXP '^[a-z]{10}$' ;
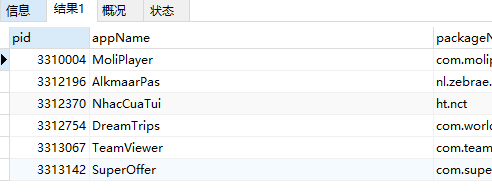
-- 查询appName字节长度为10,且都为大写英文的数据,加上BINARY即可
SELECT * from app_info where appName REGEXP BINARY '^[A-Z]{10}$';

-- 查询version_name字节长度为6,且都为数字或"." 的数据
SELECT * from app_info where version_name REGEXP '^[0-9.]{6}$';
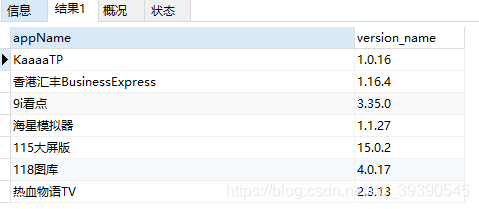
-- 查询version_name字节长度为6,且都为数字或"." 的数据;要求首位为1
SELECT * from app_info where version_name REGEXP '^1[0-9.]{5}$' ;
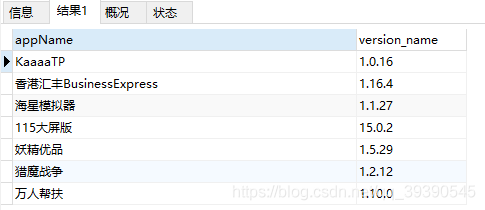
-- 查询version_name字节长度为6,且都为数字或"." 的数据;要求首位为1,末位为7
SELECT * from app_info where version_name REGEXP '^1[0-9.]{4}7$' ;
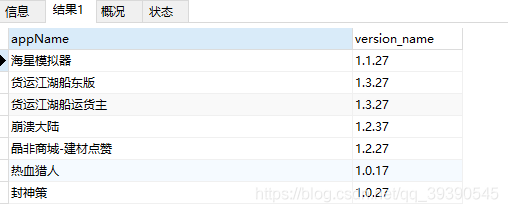
-- 查询version_name字节长度为6位以上,且都为数字或"." 的数据;要求首位为1,末位为7
SELECT * from app_info where version_name REGEXP '^1[0-9.]{4,}7$' ;
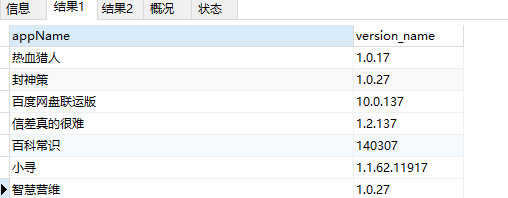
-- 查询version_name字节长度为 6 - 8 位,且都为数字或"." 的数据;要求首位为1,末位为7
SELECT * from app_info where version_name REGEXP '^1[0-9.]{4,6}7$' ;
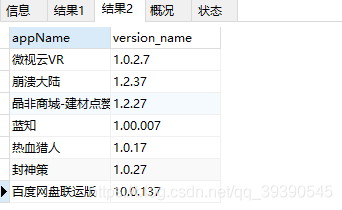
-- 首位字符不是中文的
SELECT * from app_info where appName REGEXP '^[ -~]';
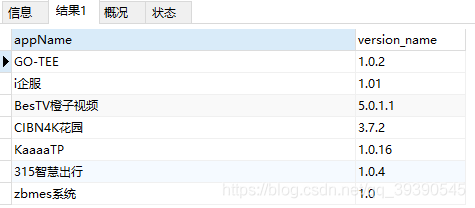
-- 首位字符是中文的
SELECT * from app_info where appName REGEXP '^[^ -~]';
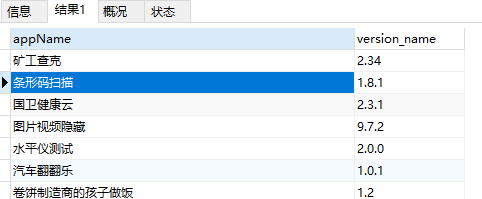
-- 查询不包含中文的数据
SELECT * from app_info where appName REGEXP '^([a-z]|[0-9]|[A-Z])+$';
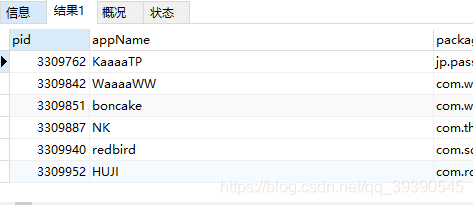
-- 以5或F开头的,且包含英文的数据
SELECT * from app_info where appName REGEXP BINARY '^[5F][a-zA-Z].';
特殊符号的匹配,例如.,需要加\\(注意是两个斜杠),但是如果在[]中可以不加:
-- 匹配name中含有.的 select * from app_info where appName regexp '\\.'; -- 匹配name中含有.的 select * from app_info where appName regexp '[.]';
3-3. 字符类匹配(posix)
mysql中有一些特殊含义的符号,可以代表不同类型的匹配:
-- 匹配name中含有数字的
select * from app_info where appName regexp '[[:digit:]]';
其他的这种字符类还有:
| 字符类 | 作用 |
| [:alnum:] | 匹配字面和数字字符。(等同于[A~Za~z0~9]) |
| [:alpha:] | 匹配字母字符。(等同于[A~Za~z]) |
| [:blank:] | 匹配空格或制表符(同[\\\t]) |
| [:cntrl:] | 匹配控制字符(ASCII0到37和127) |
| [:digit:] | 匹配十进制数字。(等同于[0-9]) |
| [:graph:] | 匹配ASCII码值范围33~126的字符。与[:print:]相似,但不包括空格字符 |
| [:print:] | 任何可打印字符 |
| [:lower:] | 匹配小写字母,等同于[a-z] |
| [:upper:] | 匹配大写字母,等同于[A-Z] |
| [:space:] | 匹配空白字符(同[\\f\\n\\r\\t\\v]) |
| [:xdigit:] | 匹配十六进制数字。等同于[0-9A-Fa-f] |
这种字符类需要主要的外层要加一层[]。
3-4. [:<:]和[:>:]
上面的字符类中有两个比较特殊的,这两个是关于位置的,[:<:]匹配词的开始,[:>:]匹配词的结束,它们和 ^、$ 不同。
后者是匹配整个整体的开头和结束,而前者是匹配一个单词的开始和结束。
-- 只能匹配整体以a开头的,例如abcd
select * from app_info where appName regexp '^a';
-- 能匹配整体以a开头的,也能匹配中间的单词以a开头,如:dance after。
select * from app_info where appName regexp '[[:<:]]a';
[[:<:]] 、 [[:>:]] 分别匹配一个单词开头和结尾的空的字符串,这个单词开头和结尾都不是包含在alnum中的字符也不能是下划线。
select "a word a" REGEXP "[[:<:]]word[[:>:]]"; -- 1(表示匹配) select "a xword a" REGEXP "[[:<:]]word[[:>:]]"; -- 0(表示不匹配) select "weeknights" REGEXP "^(wee|week)(knights|nights)$"; -- 1(表示匹配)
四、总结
好啦,本篇文章就到这里了,能看到这里的都是有缘人,希望本文能帮助到你对MySQL的理解更进一步。更多相关MySQL模糊查询内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!