1.单表查询
语法:select {*| <字段列表> } from <表1>,<表2>... where <表达式> [GROUP BY] [HAVING] [ORDER BY] [LIMIT]
创建数据库,准备表及数据
/*创建数据库*/
create database if not EXISTS students character set utf8 collate utf8_general_ci;
/*创建表*/
use students;
create table if not EXISTS student
(
stuID int(5) not null primary key,
stuName varchar(50) not null,
stuSex CHAR(10),
stuAge smallint
);
CREATE TABLE if not EXISTS courses(
couID int not null primary key auto_increment COMMENT '学号',
couName varchar(50) not null DEFAULT('大学英语'),
couHours smallint UNSIGNED COMMENT '学时',
couCredit float DEFAULT(2) COMMENT '学分'
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE utf8mb4_0900_ai_ci;
CREATE TABLE if not EXISTS stu_cou(
ID int not null primary key auto_increment,
stuID int(5) not null COMMENT '学号',
couID int not null COMMENT '课程编号',
time timestamp not null DEFAULT(now())
);
/*添加外键约束*/
alter table stu_cou add CONSTRAINT fk_stuid foreign key(stuID) REFERENCES student(stuID) ON UPDATE CASCADE ON DELETE CASCADE ;
alter table stu_cou add CONSTRAINT fk_couid foreign key(couID) REFERENCES courses(couID) ON UPDATE CASCADE ON DELETE CASCADE ;
/*插入数据*/
insert into student(stuID,stuName,stuSex,stuAge) values(1001,'张三','男',19),(1002,'李四','男',18),(1003,'王五','男',18),(1004,'黄丽丽','女',18),(1005,'李晓辉','女',19),(1006,'张敏','女',18);
insert into student VALUES(1007,'五条人','男',20),(1008,'胡五伍','女',19);
insert into courses(couID,couName,couHours,couCredit) values(50,'大学英语',64,2),(60,'计算机基础',78,2.5),(70,'Java程序设计',108,6),(80,'数据库应用',48,2.5);
insert into stu_cou(stuID,couID) values(1001,50),(1001,60),(1001,70),(1001,80),(1002,50),(1002,60),(1002,70),(1002,80),(1003,50),(1003,60),(1003,70),(1003,80),(1004,50),(1004,60),(1004,70),(1004,80),(1005,50),(1005,60),(1005,70),(1005,80),(1006,50),(1006,60),(1006,70),(1006,80);(1)简单查询
例1:查询student表中所有数据。
use students; select * from student;
例2:查询指定列的数据,查询student表中stuID,stuName两列。
select stuID,stuName from student;
例3:给列指定别名,查询student表中stuID列,指定别名为学号,stuName列,指定别名为姓名。
select stuID as '学号',stuName as '姓名' from student;
修改字段别名的语法:as+'名称'
(2)条件查询
条件:where 运算符
| 操作符 | 含义 | 范围 | 结果 |
|---|---|---|---|
| = | 等于 | 5=6 | false |
| <>或者 != | 不等于 | 5<>6 | true |
| > | 大于 | 5>6 | false |
| < | 小于 | 5<6 | true |
| >= | 大于等于 | 5>=6 | false |
| <= | 小于等于 | 5<=6 | true |
| between A and B | 在A和B之间 | between 1 and 10 | 在1~10之间,包括边界值,相当于>=1 and <=10 |
| not between A and B | 不在A和B之间 | not between 1 and 10 | 不在1~10之间,包括边界值,相当于>=1 or <=10 |
| AND | 连接条件&& | 条件1 和条件2都成立 | 都是true 才是true |
| OR | 或者|| | 条件1 和条件2有一个成立即可 | 有一个true才是true |
| IN | 以列表项的形式支持多个选择 | IN (value1,value2,…)或者 NOT IN (value1,value2,…) | 与or操作符结果类似 |
例4:查询student表中stuID为1001的记录。
select * from student where stuID=1001;
例5:查询student表中性别为男且年龄小于19岁的记录。
select * from student where stuSex='男' and stuAge<19;
例6:查询student表中性别为女或年龄等于18岁的记录。
select * from student where stuSex='女' or stuAge=18;
例7:查询student表中学号为1001和1004的记录。
SELECT * from student where stuID=1001 or stuID=1004; SELECT * from student where stuID in(1001,1004);
例8:查询student表中学号为1001到1004的记录。
SELECT * from student where stuID BETWEEN 1001 and 1004;
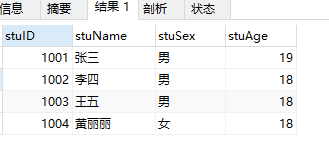
例9:查询student表中学号不包含1001到1004的记录。
SELECT * from student where stuID not BETWEEN 1001 and 1004;

(3)模糊查询
使用like关键字,通配符为
| 通配符 | 描述 |
| 百分号(%) | 替代0个、1个或多个字符 |
| 下划线(_) | 仅替代一个字符 |
例9:查询student表中所有姓张的同学的信息。
SELECT * from student where stuName like '张%';
例10:查询student表中姓名包含“丽”字的同学的信息。
SELECT * from student where stuName like '%丽%';
例11:分别查询student表中姓名包含“五”字的同学的信息。
SELECT * from student where stuName like '%五%';

'%五%'可以替代'五%'、'%五'两种情况。
(4)排序
排序的关键字是order by 字段名称,不使用where关键字,asc表示升序,desc表示降序,默认不写就是升序排列。
例12:查询student表中的记录,根据年龄进行升序排列,降序排列。
SELECT * from student ORDER BY stuAge asc; SELECT * from student ORDER BY stuAge desc;
例13:查询student表中的记录,根据年龄进行升序排列,姓名进行降序排列。
SELECT * from student ORDER BY stuAge asc,stuName desc;
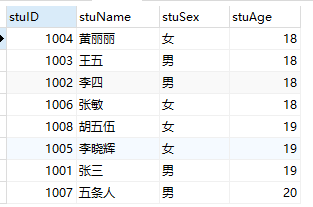
上述根据stuName字段排序的时候,字段内容是汉字,所以排序失效了,解决办法如下:
方法一:使用convert方法转换字段的字符集为gbk。
select * from student ORDER BY stuAge asc,CONVERT(stuName using gbk) desc;
方法二:修改字段的字符集为gbk。
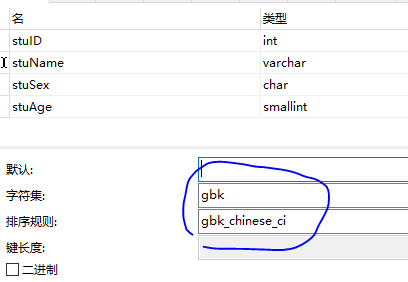
修改后运行结果为:

注意:在对多列进行排序的时候,首先第一列必须有相同的列值,才会对第二列进行排序呢。如果第一列都是唯一的值,将不会对第二列进行排序。
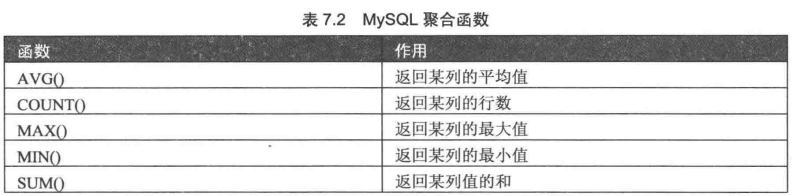
(5)聚合函数
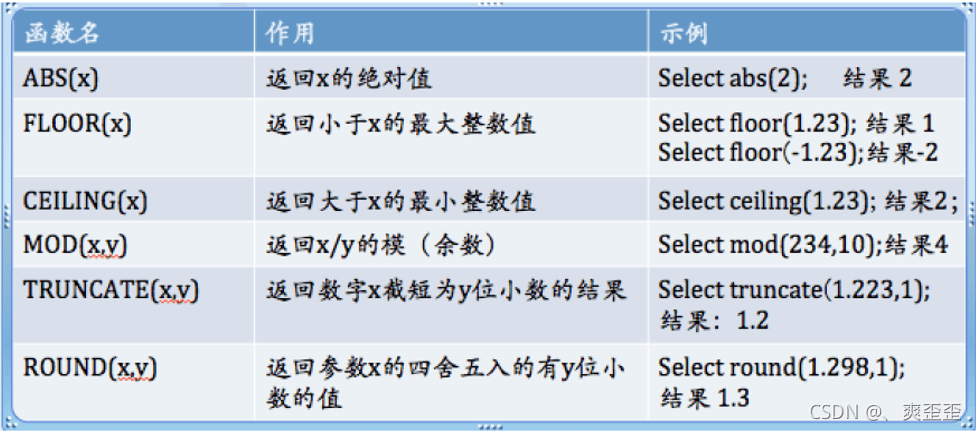
常用的聚合函数
例14:使用聚合函数查询学生总人数。
SELECT COUNT(*) as '学生总人数' from student; SELECT COUNT(stuID) as '学生总人数' from student;
例15:使用聚合函数查询课程表中所有课程的学分和。
SELECT sum(couCredit) as '总学分' from courses;
例16:分别使用聚合函数查询年龄最大的学生和年龄最小的学生的年龄。
SELECT max(stuAge) as '年龄最大的同学' from student; SELECT min(stuAge) as '年龄最小的同学' from student;
例17:使用聚合函数查询课程表中所有课程的平均学时数。
SELECT avg(couHours) as '四门课程平均学时数' from courses;
(6)分组查询
修改原数据库和表,将courses表增加一列名为grade的成绩字段,并插入随机值,运行一下命令。
alter table stu_cou add COLUMN grade FLOAT null; UPDATE stu_cou set grade=(SELECT FLOOR(50 +RAND() * 50));
如何生成指定范围的随机数
生成0-10的随机数 SELECT FLOOR(RAND() * 10) 生成10-100的随机数 SELECT FLOOR(10 +RAND() * 90)
语法:
GROUP BY 字段名 [HAVING 条件表达式]
参数:
1、字段名:是指按照该字段的值进行分组(分组是所依据的列名称)
2、HAVING条件表达式:用来限制分组后的显示,符合条件表达式的结果将被显示
核心思想:在查询SQL中指定分组的列名,然后根据该列的值(内容)进行分组,值相等的为一组。
注意:group by通常与聚合函数一起结合使用。
例18:使用分组查询输出学生性别。
SELECT stuSex as '性别' from student GROUP BY stuSex;
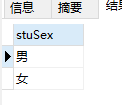
例19:使用分组查询输出学生学号和姓名。
SELECT stuID,stuName from student GROUP BY stuID;
以上两个例子中,group by后面的字段名称必须是select关键字后面出现的字段名称,除以主键字段分组以外,其他的任意两个或者两个以上的非主键字段无法使用group by进行分组,如:
SELECT stuName,stuSex from student GROUP BY stuSex;
错误提示如下:
1055 - Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'students.student.stuName' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
以上两个例子中group by单独使用时,只显示出每一组的第一条记录,所以group by单独使用时的实际意义不大,因此,一般在使用集合函数时才使用GROUP BY关键字。
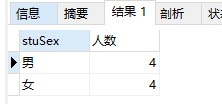
例20:分组查询学生表中男女同学的人数。
select stuSex,COUNT(stuID) as '人数' from student GROUP BY stuSex;
例21:分组查询学生表中男女同学的平均年龄,人数,男女同学年龄最大值,年龄最小值。
select stuSex,AVG(stuAge) as '平均年龄',COUNT(stuID) as '人数',MAX(stuAge) as '最大年龄',min(stuAge) as '最小年龄' from student GROUP BY stuSex;
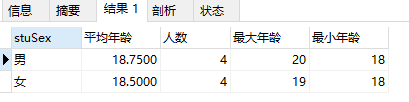
注意:从以上两个例子可知,除聚合函数之外,SELECT语句中的每个列都必须在GROUP BY子句中给出。如group by 中的stuSex列在select后必须出现。
例22:分组查询学生表中男女同学各年龄段的人数。
select stuSex,stuAge,COUNT(stuID) as '人数' from student GROUP BY stuSex,stuAge;
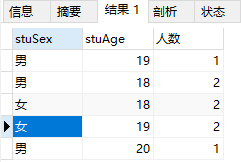
例22是使用GROUP BY可以对多个字段进行分组,GROUP BY关键字后面跟需要分组的字段。
注意:(1)MYSQL根据多字段的值来进行层次分组,分组层次从左到右
(2)即先按第一个字段分组,然后在第一个字段值相同的记录中,再根据第二个字段的值进行分组,以此类推。
多字段分组再举一个例子,修改student表增加stuColleage字段表示学院,并插入值。
alter table student add COLUMN stuColleage varchar(100) null; update student set stuColleage='大数据学院' where stuID BETWEEN 1001 and 1003; update student set stuColleage='物流学院' where stuID BETWEEN 1004 and 1006; update student set stuColleage='康养学院' where stuID BETWEEN 1007 and 1008;
分组查询学生表中各学院男女同学的人数。
select stuColleage,stuSex,COUNT(stuID) as '人数' from student GROUP BY stuColleage,stuSex;
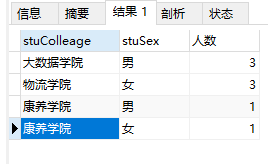
先按照stuColleage分组,再按照stuSex字段分组,返回第一个分组字段stuColleage的第一个字段值后,实际与第二个分组字段stuSex返回的值(可能是多个)进行组合,成为新的记录行。
如“康养学院”+“男”,“康养学院”+“女”,而大数据学院没有stuSex值为“女”的记录,物流学院没有stuSex值为“男”的记录,所以均只有一条记录。
若增加一个学生住址字段stuAddress,以stuAddress字段作为第二个分组的字段,则stuAddress可能会返回几十条不同信息与第一个分组的字段进行组合。
GROUP BY关键字可以和GROUP_CONCAT()函数一起使用,GROUP_CONCAT()函数会把每个分组的字段值都显示出来。
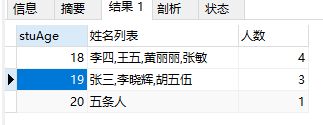
例23:分组查询学生表中各年龄段的学生姓名及人数。
select stuAge,GROUP_CONCAT(stuName) as '姓名列表',COUNT(stuID) as '人数' from student GROUP BY stuAge;
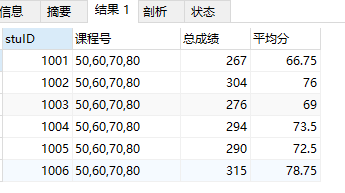
例24:按照学号进行分组,查询选课表中各科目课程号,总成绩及平均成绩。
select stuID,GROUP_CONCAT(couID) as '课程号',sum(grade) as '总成绩',avg(grade) as '平均分' from stu_cou GROUP BY stuID;
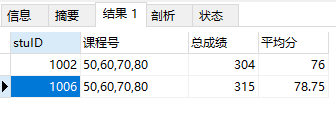
使用HAVING过滤分组,having会将分组后的数据按照分组条件进一步筛选。
例24:按照学号进行分组,查询选课表中各科目课程号,总成绩及平均成绩大于75分的记录。
select stuID,GROUP_CONCAT(couID) as '课程号',sum(grade) as '总成绩',avg(grade) as '平均分' from stu_cou GROUP BY stuID HAVING avg(grade)>75;
GROUP BY子句允许添加WITH ROLLUP修饰符,该修饰符可以对分组后各组的某个列的结果值进行汇总,并在结果中输出,即提供更高一级的聚合操作。(参考:https://www.haodaima.com/article/90130.htm)
例24:按照性别进行分组,查询学生表中男女同学的人数及总人数。
select stuSex,COUNT(stuID) as '人数' from student GROUP BY stuSex with rollup;

stuSex字段下的null代表高级别的聚合行。
(6)使用LIMIT限制查询结果的数量
从某个值开始,取出之后的N条数据,有两种形式的用法:(https://www.haodaima.com/article/226348.htm)
1.limit a,b 后缀两个参数的时候(/*参数必须是一个整数常量*/),其中a是指记录开始的偏移量,b是指从第a+1条开始,取b条记录。
2.limit b 后缀一个参数的时候,是直接取值到第多少位,类似于:limit 0,b 。
例25:查询学生表中从第2条记录开始的3条记录。
select * from student LIMIT 1,3;
例25:查询学生表中的前4条记录。
select * from student LIMIT 4;/*limit 0,4*/
(7)分页查询
https://www.haodaima.com/article/248328.htm
(8)使用distinct去除重复记录
select DISTINCT stuSex from student;
参考文章:
https://blog.csdn.net/ccx_nc/article/details/120922391
https://blog.csdn.net/DianLanHong/article/details/119788185 MySQL where in 用法详解
https://www.cnblogs.com/yangjianbo/articles/15739877.html
https://blog.csdn.net/weixin_42352842/article/details/113635581
https://blog.csdn.net/Hudas/article/details/124370701 [Mysql] LIKE与通配符
https://www.cnblogs.com/bigbigbigo/p/10953037.html MySQL 聚合函数(二)Group By的修饰符——ROLLUP
到此这篇关于MySQL查询数据(单表查询)的文章就介绍到这了,更多相关mysql 查询数据内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!