技术面试题
1.Hadoop中有哪些组件?
Hadoop=HDFS+Yarn+MapReduce+Hive+Hbase+...
1).HDFS:分布式文件存储系统
主:namenode,secondarynamenode
从:datanode
2).Yarn:分布式资源管理系统,用于同一管理集群中的资源(内存等)
主:ResourceManager
从:NodeManager
3).MapReduce:Hadoop的计算框架,用map和reduce方式实现数据的全局汇总
4).Zookeeper:分布式协调服务,用于维护集群配置的一致性、任务提交的事物性、集群中服务的地址管理、集群管理等
主:QuorumPeerMain
从:QuorumPeerMain
5).Hbase:Hadoop下的分布式数据库,类似于NoSQL
主:HMaster,HRegionserver,Region
7).Hive:分布式数据仓库,其实说白了就是一个数据分析工具,底层用的还是MapReduce
8).Sqoop:用于将传统数据库中数据导入到hbase或者Hdfs中一个导入工具
9).Spark:基于内存的分布式处理框架
主:Master
从:Worker
2.Hdfs中角色有哪些?
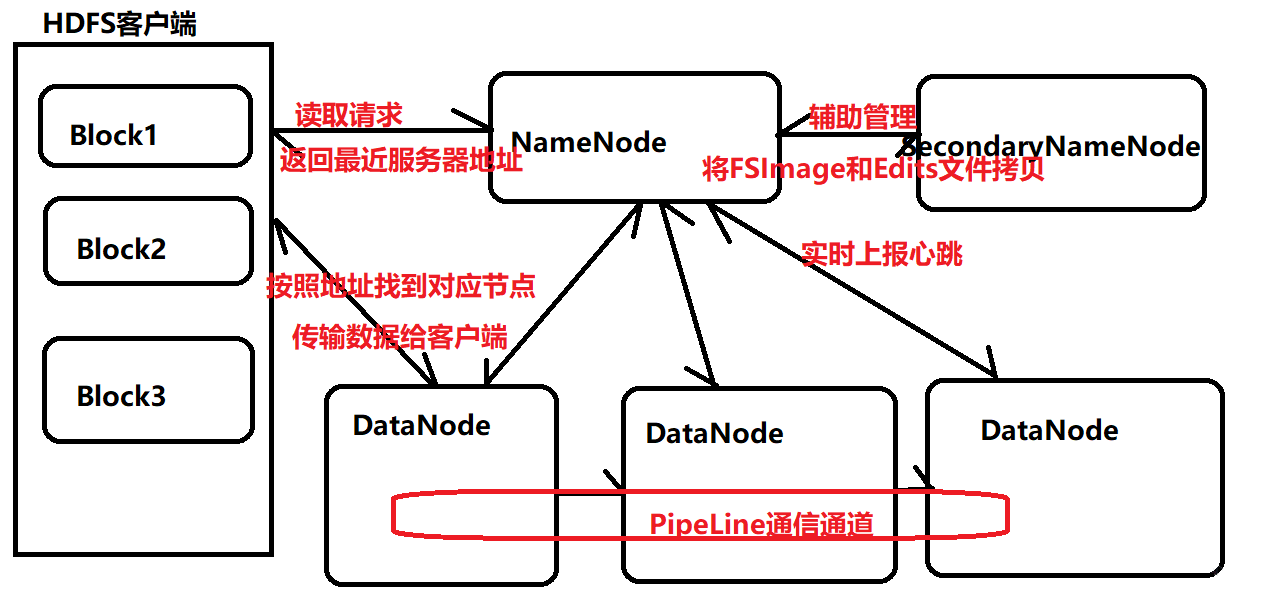
NameNode:管理元数据信息,给子节点分配任务(FSImage是主节点启动时对整个文件系统的快照,Edits是修改记录)
DataNode:负责数据存储,实时上报心跳给主节点
SecondaryNameNode:
1)首先,它定时到NameNode去获取edit logs,并更新到fsimage上。一旦它有了新的fsimage文件,它将其拷贝回 NameNode中。
2) NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。
3.Hdfs和Yarn有什么区别?
1)Hdfs是分布式文件存储系统,是用来存储文件的;
2)Yarn是一个资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和 数据共享等方面带来了巨大好处
4.MapReduce的shuffle过程?
从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。
1).Collect阶段:将MapTask的结果输出到默认大小为100M的环形缓冲区,保存的是key/value,Partition分区信息等。
2).Spill阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据 进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序。
3).Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件。
4).Copy阶段:ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据,这些数据默认会 保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上。
5).Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
6).Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序, ReduceTask只需保证Copy的数据的最终整体有效性即可。
5.MapReduce的Partition和Combine有什么区别?
1)combine分为map端和reduce端,作用是把同一个key的键值对合并在一起,可以自定义,该类的主要功能是合并相 同的key键
2)partition是分割map每个节点的结果,按照key分别映射给不同的reduce,也是可以自定义的,partition的作用就是把 这些数据归类
6.Hadoop的高可用模式说一下?
7.Zookeeper在Hadoop中的作用?
1)Zookeepe主要用来解决分布式应用中经常遇到的数据管理问题,如集群管理、统一命名服务、分布式配置管理、 分布式消息队列、分布式锁、分布式协调等。
2)Zookeeper是一个由多个server组成的集群,一个leader,多个follower,每个server保存一份数据副本,全局数据 一致、分布式读写,更新请求转发,由leader实施。
8.Sqoop的底层原理?
是用来实现结构型数据(如关系数据库)和Hadoop之间进行数据迁移的工具。它充分利用了MapReduce的并行特 点以批处理的方式加快数据的传输,同时也借助MapReduce实现了容错
9.Sqoop是怎么连接的关系型数据库?
sqoop import-all-tables –connect jdbc:mysql://192.168.52.110/hivemetadb --username root -password root
10.Java中抽象类怎么理解?
抽象类不能实例化,继承的关键字仍然是extends,而且继承过后可以不覆盖方法,只是使用继承而来的方法
A:抽象类和抽象方法必须用abstract关键字修饰;
B:抽象类中不一定有抽象方法,但是有抽象方法的类必须定义为抽象类;
C:抽象类不能直接实例化;(可以通过子类(重写方法后的子类)的多态方式实例化);
1.它不是具体的;
2.抽象类有构造方法,用于子类访问父类数据的初始化;
D:抽象类的子类;
1.如果不想重写抽象方法,该子类必须是抽象类;
2.成为具体类则必须重写所有的抽象方法;
11.Hdfs的块的大小多少能不能改成10M?
不能,假如数据块设置过少,那需要读取的数据块就比较多,由于数据块在硬盘上非连续存储,普通硬盘因为需要 移动磁头,所以随机寻址较慢,读越多的数据块就增大了总的硬盘寻道时间。当硬盘寻道时间比io时间还要长的多 时,那硬盘寻道时间就成了系统的一个瓶颈
12.你的项目中你的Hive仓库怎么设计的?分几层?
1 )源数据层:此层数据无任何更改,不对外开放,为临时存储层,是接口数据的临时存储区域,为后一步的数据处 理做准备。
2) 数据仓库层(DW):DW层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗(去除了 杂质后的数据。
2) 数据应用层(DA或APP):前端应用直接读取的数据源;根据报表、专题分析需求而计算生成的数据。
13.Hive中的内表和外表的区别?
1)在删除内部表的时候,Hive将会把属于表的元数据和数据全部删掉;
2)而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的
14.分区表和分桶表有什么区别?
1)分区就是分文件夹,在表文件夹下多一个文件夹,分区字段是虚拟的,用于标识文件,分区字段一定不是表中存 在的字段,否则会便宜报错;
2)分桶功能默认不开启,需要手动开启,分桶个数自定义,是相对于分区更细粒度的划分,是分文件;
15.Hive优化假如有数据倾斜怎么优化?
16.假如你的分析的数据有很多小文件,你用SQL语句分析的话会出现什么情况?
17.能说说你项目中的模型表是怎么设计的吗?
18.Yarn除了在Hadoop中应用,还有什么用到了Yarn?
19.Azkaban的特性?
1、Web用户界面
2、方便上传工作流
3、方便设置任务之间的关系
4、调度工作流
5、认证/授权(权限的工作)
6、能够杀死并重新启动工作流
7、模块化和可插拔的插件机制
8、项目工作区
9、工作流和任务的日志记录和审计
20.怎么查看本机内存CPU使用情况?
free -m
21.怎么查看目录下的所有详细情况?
先使用 ls -a 查看当前目录下的所有文件;
然后使用 ls -a -l 查看所有文件的详细信息,每一行是一个文件的所有信息;
再使用 ls -a -l -h 查看所有文件的详细信息
22.Hbase索引和Hive索引有什么区别?
1.Hive中的表为纯逻辑表,仅仅对表的元数据进行定义。Hive没有物理存储的功能,它完全依赖HDFS和 MapReduce。HBase表则是物理表,适合存放非结构化的数据。
2.Hive是在MapReduce的基础上对数据进行处理;而HBase为列模式,这样使得对海量数据的随机访问变得可行。
3.HBase的存储表存储密度小,因而用户可以对行定义成不同的列;而Hive是逻辑表,属于稠密型,即定义列数,每 一行对列数都有固定的数据。
4.Hive使用Hadoop来分析处理数据,而Hadoop系统是批处理系统,所以数据处理存在延时的问题;而HBase是准实 时系统,可以实现数据的实时查询。
5.Hive没有row-level的更新,它适用于大量append-only数据集(如日志)的批任务处理。而基于HBase的查询,支 持和row-level的更新。
6.Hive全面支持SQL,一般可以用来进行基于历史数据的挖掘、分析。而HBase不适用于有join,多级索引,表关系 复杂的应用场景。
23.数据量大如何用Order by 全局排序?
24.Kafka,Flume中组件包括哪些?
Kafka组件:
Topic :消息根据Topic进行归类
Producer:发送消息者
Consumer:消息接受者
broker:每个kafka实例(server)
Zookeeper:依赖集群保存meta信息。
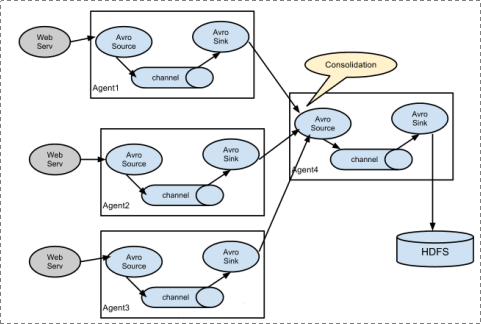
Flume组件:
Agent:
Source:
Channel:
Sink:
25.查看内存使用情况/磁盘使用情况命令行?
free -m
26.Hdfs的读写流程?
27.Flume中Agent各个组件包含什么?
28.Hive数据倾斜如何处理?内部表,外部表,分区,分桶
29.order by ,sort by ,destribute by,cluster by 区别?
1)order by
order by会对输入做全局排序,因此只有一个Reducer(多个Reducer无法保证全局有序),然而只有一个Reducer,会导 致当输入规模较大时,消耗较长的计算时间。
2)sort by
sort by不是全局排序,其在数据进入reducer前完成排序,sort by只会保证每个reducer的输出有序,并不保证全局有 序。sort by的数据只能保证在同一个reduce中的数据可以按指定字段排序。
3)distribute by
distribute by是控制在map端如何拆分数据给reduce端的。hive会根据distribute by后面列,对应reduce的个数进行分 发,默认是采用hash算法。sort by为每个reduce产生一个排序文件。在有些情况下,你需要控制某个特定行应该到哪个 reducer,这通常是为了进行后续的聚集操作。distribute by刚好可以做这件事。因此,distribute by经常和sort by配合 使 用。
4)cluster by
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是倒叙排序,不能指定排序规则为ASC或 者DESC。
30.Sqoop怎么连接数据库?
31.where和having的区别?
1) “Where” 是一个约束声明,使用Where来约束来自数据库的数据,Where是在结果返回之前起作用的,且Where中不能使 用聚合函数。
2)“Having”是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作,在Having中可以使用聚合函数。
32.左连接和右连接的区别?
左连接where只影向右表,右连接where只影响左表
1)Left Join
select * from tbl1 Left Join tbl2 where tbl1.ID = tbl2.ID
左连接后的检索结果是显示tbl1的所有数据和tbl2中满足where 条件的数据。
2)Right Join
select * from tbl1 Right Join tbl2 where tbl1.ID = tbl2.ID
检索结果是tbl2的所有数据和tbl1中满足where 条件的数据。
33.Hive中如何对大量数据进行全局排序?
34.Linux指令
35.Shell,Hive,Hbase,Spark,Sqoop
36.机架感应机制
项目面试题
1.大概介绍一下项目;
2.hbase表你们是怎么存数据的?一天数据量是多少?这么多数据你们都存hbase里吗?一开始就是个文件,hbase是表结构,那你是怎么去获取数据然后给存成表结构的?
3.假如现在我要查询每个月的每个片区里订单成交量最高的那个司机ID,你怎么实现?
4.hive怎么读取数据的?我要只存里边我需要的数据,你给我想下怎么优化?
5.你都用过哪些ETL工具?怎么用的?就像flume是怎么获取数据的,你怎么配置的?那kafka怎么读取数据的?hive是直接从kafka里获取数据吗?
6.你建过外表吗?怎么建的?为什么要建外表?
7.你会写shell吗?写过哪些?
8.你应该也经常用linux命令吧,都用过哪些?我现在要查所有后缀是.txt的文件名,怎么查?grep用过吗?
9.我现在不想查司机,我想查订单,怎么去设计hbase表?