前言:
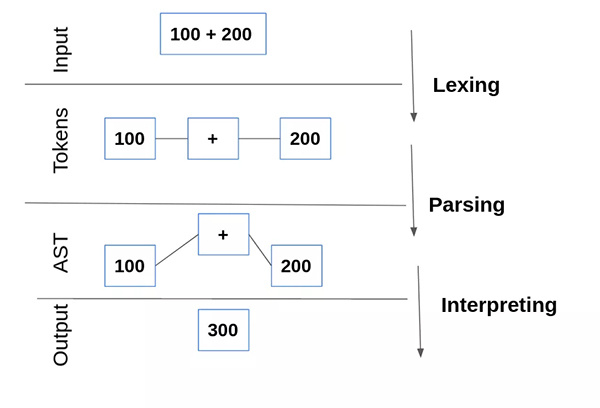
计算机只能理解机器码。归根结底,编程语言只是一串文字,目的是为了让人类更容易编写他们想让计算机做的事情。真正的魔法是由编译器和解释器完成,它们弥合了两者之间的差距。解释器逐行读取代码并将其转换为机器码。
在本文中,我们将设计一个可以执行算术运算的解释器。
我们不会重新造轮子。文章将使用由 David M. Beazley 开发的词法解析器 ——PLY(Python Lex-Yacc(https://github.com/dabeaz/ply))。
PLY 可以通过以下方式下载:
$ pip install ply
我们将粗略地浏览一下创建解释器所需的基础知识。欲了解更多,请参阅这个 GitHub 仓库(https://github.com/dabeaz/ply)。
1.标记(Token)
标记是为解释器提供有意义信息的最小字符单位。标记包含一对名称和属性值。
让我们从创建标记名称列表开始。这是一个必要的步骤。
tokens = ( # 数据类型 "NUM", "FLOAT", # 算术运算 "PLUS", "MINUS", "MUL", "DIV", # 括号 "LPAREN", "RPAREN", )
2.词法分析器(Lexer)
将语句转换为标记的过程称为标记化或词法分析。执行词法分析的程序是词法分析器。
# 标记的正则表达
t_PLUS = r"\+"
t_MINUS = r"\-"
t_MUL = r"\*"
t_DIV = r"/"
t_LPAREN = r"\("
t_RPAREN = r"\)"
t_POW = r"\^"
# 忽略空格和制表符
t_ignore = " \t"
# 为每个规则添加动作
def t_FLOAT(t):
r"""\d+\.\d+"""
t.value = float(t.value)
return t
def t_NUM(t):
r"""\d+"""
t.value = int(t.value)
return t
# 未定义规则字符的错误处理
def t_error(t):
# 此处的 t.value 包含未标记的其余输入
print(f"keyword not found: {t.value[0]}\nline {t.lineno}")
t.lexer.skip(1)
# 如果遇到 \n 则将其设为新的一行
def t_newline(t):
r"""\n+"""
t.lexer.lineno += t.value.count("\n") 为导入词法分析器,我们将使用:
import ply.lex as lex
t_ 是一个特殊的前缀,表示定义标记的规则。每条词法规则都是用正则表达式制作的,与 Python 中的 re 模块兼容。正则表达式能够根据规则扫描输入并搜索符合的符号串。正则表达式定义的文法称为正则文法。正则文法定义的语言则称为正则语言。
定义好了规则,我们将构建词法分析器:
data = 'a = 2 +(10 -8)/1.0' lexlexer = lex.lex() lexer.input(data) while tok := lexer.token(): print(tok)
为了传递输入字符串,我们使用lexer.input(data)。lexer.token() 将返回下一个 LexToken 实例,最后返回 None。根据上述规则,代码 2 + ( 10 -8)/1.0 的标记将是:

紫色字符代表的是标记的名称,其后是标记的具体内容。
3.巴科斯-诺尔范式(Backus-Naur Form,BNF)
大多数编程语言都可以用上下文无关文法来编写。它比常规语言更复杂。对于上下文无关文法,我们用上下文无关语法,它是描述语言中所有可能语法的规则集。BNF 是一种定义语法的方式,它描述了编程语言的语法。
让我们看看例子:
symbol : alternative1 | alternative2 …
根据产生式,: 的左侧被替换为右侧的其中一个值替换。右侧的值由 | 分隔(可理解为 symbol 定义为 alternative1 或 alternative2或…… 等等)。
对于我们的这个算术解释器,语法规格如下:
expression : expression '+' expression | expression '-' expression | expression '/' expression | expression '*' expression | expression '^' expression | +expression | -expression | ( expression ) | NUM | FLOAT
输入的标记是诸如 NUM、FLOAT、+、-、*、/ 之类的符号,称作终端(无法继续分解或产生其他符号的字符)。一个表达式由终端和规则集组成,例如 expression 则称为非终端。
4.解析器(Parser)
我们将使用 YACC(Yet Another Compiler Compiler) 作为解析器生成器。导入模块:import ply.yacc as yacc。
from operator import (add, sub, mul, truediv, pow)
# 我们的解释器支持的运算符列表
ops = {
"+": add,
"-": sub,
"*": mul,
"/": truediv,
"^": pow,
}
def p_expression(p):
"""expression : expression PLUS expression
| expression MINUS expression
| expression DIV expression
| expression MUL expression
| expression POW expression"""
if (p[2], p[3]) == ("/", 0):
# 如果除以 0,则将“INF”(无限)作为值
p[0] = float("INF")
else:
p[0] = ops[p[2]](p[1], p[3])
def p_expression_uplus_or_expr(p):
"""expression : PLUS expression %prec UPLUS
| LPAREN expression RPAREN"""
p[0] = p[2]
def p_expression_uminus(p):
"""expression : MINUS expression %prec UMINUS"""
p[0] = -p[2]
def p_expression_num(p):
"""expression : NUM
| FLOAT"""
p[0] = p[1]
# 语法错误时的规则
def p_error(p):
print(f"Syntax error in {p.value}") 在文档字符串中,我们将添加适当的语法规范。p 列表中的的元素与语法符号一一对应,如下所示:
expression : expression PLUS expression p[0] p[1] p[2] p[3]
在上文中,%prec UPLUS 和 %prec UMINUS 是用来表示自定义运算的。%prec 即是 precedence 的缩写。在符号中本来没有 UPLUS 和 UMINUS 这个说法(在本文中这两个自定义运算表示一元正号和符号,其实 UPLUS 和 UMINUS 只是个名字,想取什么就取什么)。之后,我们可以添加基于表达式的规则。YACC 允许为每个令牌分配优先级。
我们可以使用以下方法设置它:
precedence = (
("left", "PLUS", "MINUS"),
("left", "MUL", "DIV"),
("left", "POW"),
("right", "UPLUS", "UMINUS")
) 在优先级声明中,标记按优先级从低到高的顺序排列。PLUS 和 MINUS 优先级相同并且具有左结合性(运算从左至右执行)。MUL 和 DIV 的优先级高于 PLUS 和 MINUS,也具有左结合性。POW 亦是如此,不过优先级更高。UPLUS 和 UMINUS 则是具有右结合性(运算从右至左执行)。
要解析输入我们将使用:
parser = yacc.yacc() result = parser.parse(data) print(result)
完整代码如下:
#####################################
# 引入模块 #
#####################################
from logging import (basicConfig, INFO, getLogger)
from operator import (add, sub, mul, truediv, pow)
import ply.lex as lex
import ply.yacc as yacc
# 我们的解释器支持的运算符列表
ops = {
"+": add,
"-": sub,
"*": mul,
"/": truediv,
"^": pow,
}
#####################################
# 标记集 #
#####################################
tokens = (
# 数据类型
"NUM",
"FLOAT",
# 算术运算
"PLUS",
"MINUS",
"MUL",
"DIV",
"POW",
# 括号
"LPAREN",
"RPAREN",
)
#####################################
# 标记的正则表达式 #
#####################################
t_PLUS = r"\+"
t_MINUS = r"\-"
t_MUL = r"\*"
t_DIV = r"/"
t_LPAREN = r"\("
t_RPAREN = r"\)"
t_POW = r"\^"
# 忽略空格和制表符
t_ignore = " \t"
# 为每个规则添加动作
def t_FLOAT(t):
r"""\d+\.\d+"""
t.value = float(t.value)
return t
def t_NUM(t):
r"""\d+"""
t.value = int(t.value)
return t
# 未定义规则字符的错误处理
def t_error(t):
# 此处的 t.value 包含未标记的其余输入
print(f"keyword not found: {t.value[0]}\nline {t.lineno}")
t.lexer.skip(1)
# 如果看到 \n 则将其设为新的一行
def t_newline(t):
r"""\n+"""
t.lexer.lineno += t.value.count("\n")
#####################################
# 设置符号优先级 #
#####################################
precedence = (
("left", "PLUS", "MINUS"),
("left", "MUL", "DIV"),
("left", "POW"),
("right", "UPLUS", "UMINUS")
)
#####################################
# 书写 BNF 规则 #
#####################################
def p_expression(p):
"""expression : expression PLUS expression
| expression MINUS expression
| expression DIV expression
| expression MUL expression
| expression POW expression"""
if (p[2], p[3]) == ("/", 0):
# 如果除以 0,则将“INF”(无限)作为值
p[0] = float("INF")
else:
p[0] = ops[p[2]](p[1], p[3])
def p_expression_uplus_or_expr(p):
"""expression : PLUS expression %prec UPLUS
| LPAREN expression RPAREN"""
p[0] = p[2]
def p_expression_uminus(p):
"""expression : MINUS expression %prec UMINUS"""
p[0] = -p[2]
def p_expression_num(p):
"""expression : NUM
| FLOAT"""
p[0] = p[1]
# 语法错误时的规则
def p_error(p):
print(f"Syntax error in {p.value}")
#####################################
# 主程式 #
#####################################
if __name__ == "__main__":
basicConfig(level=INFO, filename="logs.txt")
lexlexer = lex.lex()
parser = yacc.yacc()
while True:
try:
result = parser.parse(
input(">>>"),
debug=getLogger())
print(result)
except AttributeError:
print("invalid syntax") 到此这篇关于利用 Python 开发一个 Python 解释器的文章就介绍到这了,更多相关Python 解释器内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!