介绍
本文全部代码地址
布隆过滤器是一种高效的数据结构,用于判断一个元素是否存在于一个集合中 它的主要优点是速度快,空间占用少,因此在需要快速判断某个元素是否在
介绍
布隆过滤器是一种高效的数据结构,用于判断一个元素是否存在于一个集合中.它的主要优点是速度快,空间占用少,因此在需要快速判断某个元素是否在集合中的场合得到广泛引用.
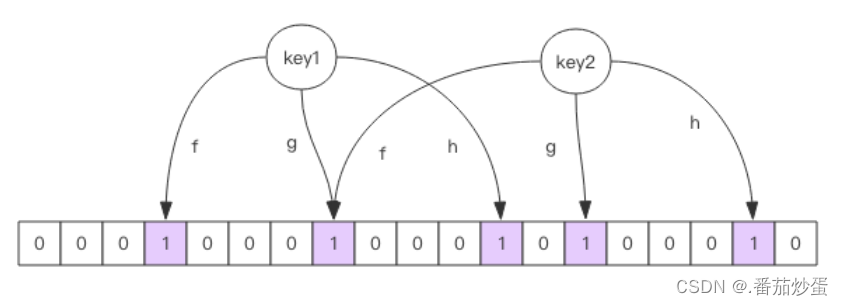
布隆过滤器就是一个大型的位数组和几个不一样的无偏hash函数.所谓无偏就是能够把元素的hash值算的比较均匀.当布隆过滤器说某个值存在时,这个值可能不存在;当它说某个值不存在时,那就肯定不存在.
向布隆过滤器中添加key时,会使用多个hash函数对key进行hash算得一个整数索引值然后对应位数数组长度进行取模运算得到一个位置,每个hash函数都会算得一个不同的位置.再把位数组的这几个位置都置为1就完成了add操作.
向布隆过滤器询问key是否存在时,跟add一样,也会把hash的几个位置都算出来,看看数组中这几个位置是否都为1,只要有一个位为0,那么就说明布隆过滤器中这个key不存在.如果都是1,这并不能说明这个key就一定存在,只是极有可能存在,因为这些位置被置为1可能是因为其他的key存在所致.如果这个位数组长度比较大,存在概率就会很大,如果这个位数组长度比较小,存在的概率就会降低.
这种方法适用于数据命中不高、数据相对固定、实时性低(通常是数据集较大) 的应用场景,代码维护较为复杂,但是缓存空间占用很少.
实现
初始化数据
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `user` VALUES ('be079b29ddc111eda9b20242ac110003', '张三', '北京市海淀区xx街道123号');
INSERT INTO `user` VALUES ('be079b53ddc111eda9b20242ac110003', '李四', '上海市徐汇区xx路456号');
INSERT INTO `user` VALUES ('be079b95ddc111eda9b20242ac110003', '王五', '广州市天河区xx街道789号');
INSERT INTO `user` VALUES ('be079ba4ddc111eda9b20242ac110003', '赵六', '深圳市南山区xx路321号');
INSERT INTO `user` VALUES ('be079bb8ddc111eda9b20242ac110003', '周七', '成都市高新区xx街道654号');
INSERT INTO `user` VALUES ('be079bc5ddc111eda9b20242ac110003', '黄八', '武汉市江汉区xx街道234号');
INSERT INTO `user` VALUES ('be079bd4ddc111eda9b20242ac110003', '罗九', '南京市秦淮区xx路567号');
INSERT INTO `user` VALUES ('be079be2ddc111eda9b20242ac110003', '钱十', '重庆市渝北区xx街道890号');
INSERT INTO `user` VALUES ('be079befddc111eda9b20242ac110003', '周十一', '长沙市岳麓区xx路432号');
INSERT INTO `user` VALUES ('be079bfbddc111eda9b20242ac110003', '吴十二', '西安市雁塔区xx街道765号');
代码实现
这里只展示关于布隆过滤器的核心代码
public class BloomFilterHelper<T> {
private int numHashFunctions;
private int bitSize;
private Funnel<T> funnel;
public BloomFilterHelper(Funnel<T> funnel, int expectedInsertions, double fpp) {
Preconditions.checkArgument(funnel != null, "funnel不能为空");
this.funnel = funnel;
// 计算bit数组长度
bitSize = optimalNumOfBits(expectedInsertions, fpp);
// 计算hash方法执行次数
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
public int[] murmurHashOffset(T value) {
int[] offset = new int[numHashFunctions];
long hash64 = Hashing.murmur3_128().hashObject(value, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int nextHash = hash1 + i * hash2;
if (nextHash < 0) {
nextHash = ~nextHash;
}
offset[i - 1] = nextHash % bitSize;
}
return offset;
}
/**
* 计算bit数组长度
*/
private int optimalNumOfBits(long n, double p) {
if (p == 0) {
// 设定最小期望长度
p = Double.MIN_VALUE;
}
return (int) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
/**
* 计算hash方法执行次数
*/
private int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
}@Slf4j
@Configuration
public class BloomFilterConfig implements InitializingBean {
@Autowired
private StringRedisTemplate template;
@Autowired
private UserService userService;
public static final String BLOOM_REDIS_PREFIX = "bloom_user";
@Bean
public BloomFilterHelper<String> initBloomFilterHelper() {
return new BloomFilterHelper<>((Funnel<String>) (from, into) -> into.putString(from, Charsets.UTF_8)
.putString(from, Charsets.UTF_8), 1000000, 0.01);
}
/**
* 布隆过滤器bean注入
*
* @return
*/
@Bean
public BloomRedisService bloomRedisService() {
BloomRedisService bloomRedisService = new BloomRedisService();
bloomRedisService.setBloomFilterHelper(initBloomFilterHelper());
bloomRedisService.setRedisTemplate(template);
return bloomRedisService;
}
/**
* 初始化方法,将数据库中的id加入到布隆过滤器
* 也可以不必实现{@link InitializingBean}使用{@link javax.annotation.PostConstruct}注解
*
* @throws Exception
*/
@Override
public void afterPropertiesSet() throws Exception {
List<String> idList = userService.getAllUserId();
log.info("加载用户id到布隆过滤器当中,size:{}", idList.size());
if (!CollectionUtils.isEmpty(idList)) {
idList.forEach(item -> {
bloomRedisService().addByBloomFilter(BLOOM_REDIS_PREFIX, item);
});
}
}
}public class BloomRedisService {
private StringRedisTemplate redisTemplate;
private BloomFilterHelper bloomFilterHelper;
public void setBloomFilterHelper(BloomFilterHelper bloomFilterHelper) {
this.bloomFilterHelper = bloomFilterHelper;
}
public void setRedisTemplate(StringRedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
}
/**
* 根据给定的布隆过滤器添加值
*/
public <T> void addByBloomFilter(String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
redisTemplate.opsForValue().setBit(key, i, true);
}
}
/**
* 根据给定的布隆过滤器判断值是否存在
*/
public <T> boolean includeByBloomFilter(String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
if (!redisTemplate.opsForValue().getBit(key, i)) {
return false;
}
}
return true;
}
}@Configuration
public class InterceptorConfiguration implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
//注册拦截器
registry.addInterceptor(authInterceptorHandler())
.addPathPatterns("/user/get/{id}");
}
@Bean
public BloomFilterInterceptor authInterceptorHandler(){
return new BloomFilterInterceptor();
}
}
@Slf4j
public class BloomFilterInterceptor implements HandlerInterceptor {
@Autowired
private BloomRedisService bloomRedisService;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String currentUrl = request.getRequestURI();
PathMatcher matcher = new AntPathMatcher();
//解析出pathvariable
Map<String, String> pathVariable = matcher.extractUriTemplateVariables("/user/get/{id}", currentUrl);
//布隆过滤器存储在redis中
String id = pathVariable.get("id");
if (bloomRedisService.includeByBloomFilter(BloomFilterConfig.BLOOM_REDIS_PREFIX, id)) {
log.info("{}极有可能存在,继续向下执行;", id);
return true;
}
/*
* 不在本地布隆过滤器当中,直接返回验证失败
* 设置响应头
*/
log.info("{}不存在,直接返回失败;", id);
response.setHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE);
response.setCharacterEncoding(StandardCharsets.UTF_8.toString());
response.setStatus(HttpStatus.NOT_FOUND.value());
Result res = new Result(HttpStatus.NOT_FOUND.value(), "用户不存在!", null);
String result = new ObjectMapper().writeValueAsString(res);
response.getWriter().print(result);
return false;
}
}测试
存在的数据


不存在的数据


到此这篇关于Java中的布隆过滤器原理实现和应用的文章就介绍到这了,更多相关Java布隆过滤器内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!
![用户权限管理设计[图文说明]](https://cdnss.haodaima.top/uploadfile/2024/0318/20240318032432810.jpg)