1.什么是并行计算
传统并行计算:共享同一个数据,通过锁来控制数据的读写,难度大,容易导致死锁,拓展性差。但是是实时的,细颗粒度计算,计算密集型
Mapreduce:对机器的要求低,拓展性难,便宜,拓展性强,批处理场景,非实时,数据密集型(傻大)
map:分配工作任务给不同的人,并让其完成工作(工作相互独立,不互相为上下环节)
reduce:把不同的结果集合并 再加上分布式
2.现在mapreduce能做什么?
map:映射
1.如小写字母变成大写字母 map
2.把年龄小于16岁的都去掉 map
3.把美元变成人民币 y=x∗6.3y=x * 6.3y=x∗6.3 map
4.地址库的一个翻译:省市县 map
5.(只要是一些处理数据相关的,都应当是在map上)
reduce:做比较,工作整合,上下游
1.统计年薪最高的人 (一个组)key
2.按照男女计算平均年龄 (俩个组)key
3.排序 reduce
有些操作放在map、reduce里面都可以
a-------->a----->A
map--------- reduce ×
前提:尽量要减少数据的流动,reduce阶段数据越少越好,能在map做就在map做掉
数据SQL:
Select name ,age,gender from people where id =3
1.project(投射)map完成
Select name ,age,gender
2.filter(过滤)map完成
id=3
3.key(汇集)
如:Select avg(age),gender from peoplemap:age,gender ---project
key:gender(F,M) //分为man和femalereduce:按照key进行汇集 F(25,38,23),M(45,23)
reduce:avg
如:Select max(age),gender from people这里和上面差不多,但是就没有key了放在同一个地方
oss和hive的区别?
在文件系统上
实验部分:
1. 搭建各类环境
为了模拟真实情况,我这里搭建了分布式的hadoop集群,分别有三台机器。一台做master,一台做slave。

2. 搭建、配置zookeeper

3. 启动zookeeper
/usr/zookeeper/zookeeper-3.4.10/bin/zkServer.sh start

4. 安装配置java

5. 主从节点格式化

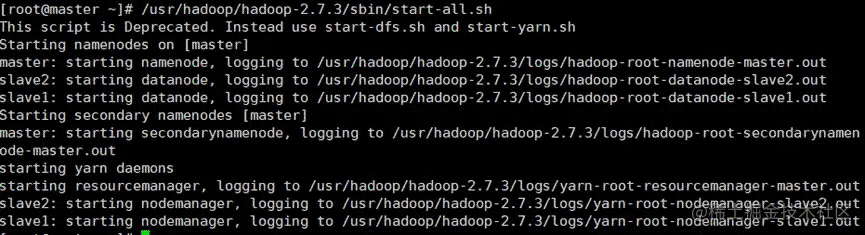
6. 启动集群
/usr/hadoop/hadoop-2.7.3/sbin/start-all.sh
7. 安装Scala

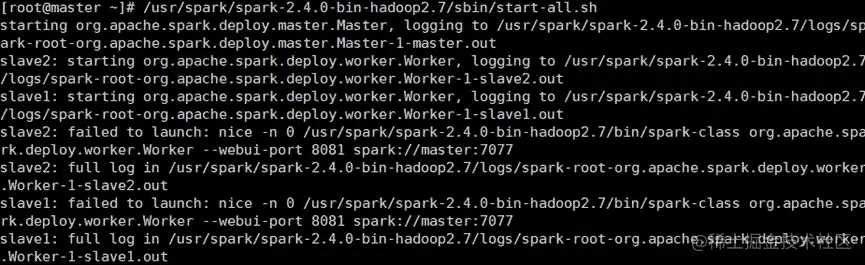
8. 启动spark集群
/usr/spark/spark-2.4.0-bin-hadoop2.7/sbin/start-all.sh
9. jps查看已经启动的

以上就是Mapreduce分布式并行编程的详细内容,更多关于Mapreduce分布式的资料请关注好代码网其它相关文章!