1. 何为领域驱动设计:
怎么让软件和领域和谐相处:最佳的方式是让软件成为领域的反射(映射),体现领域里重要的核心概念和元素,并精确实现它们之间的关系。
领域模型不是一副具体的图,它是那幅图要极力去传达的那个思想!
2. 通用语言:
由软件架构师、开发人员和领域专家构成的开发团队,需要一种语言来统一他们的行动,以帮助他们创建一个模型,并使用代码来表现模型。
一个明智的沟通模型的方式是创建一些小的图,让每副小图包含模型的一个子集。这些图会包含若干类以及它们之间的关系,然后向图中添加文本,文本将解释图所不能表现的行为和约束。
3. 模型驱动设计:
紧密关联领域建模和设计,模型在创建时就考虑到软件和设计(选择一个能够适当在软件中表现的模型,代码和其下的模型紧密关联让代码更有意义并与模型更相关)
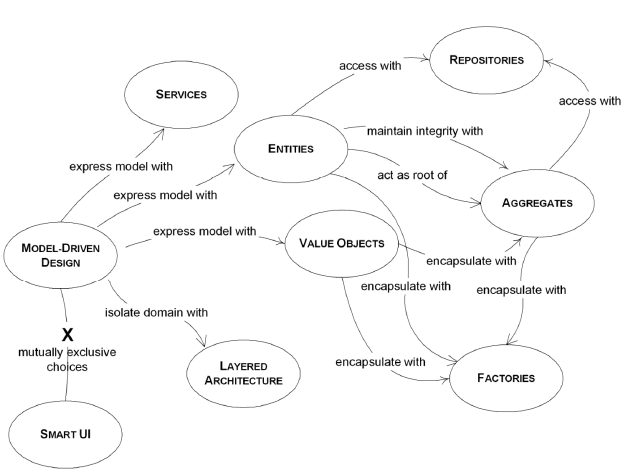
1)模型驱动设计的基本构成要素:
2)分层架构:
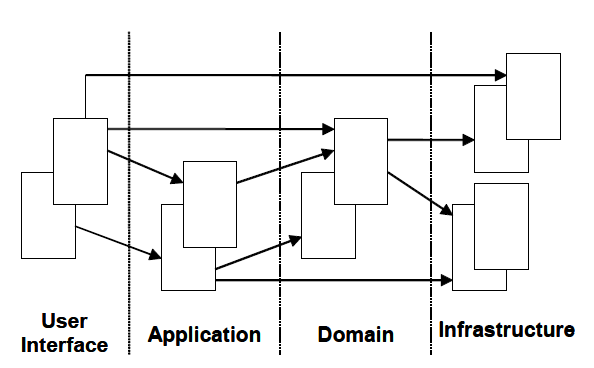
具体职能如下:
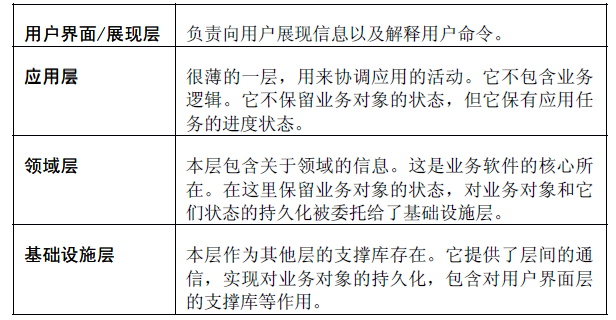
3)实体:看上去好像拥有标识符的一类对象,它的标识符在历经软件的各种状态后仍能保持一致。(能够跨越系统的生命周期甚至是超越软件系统的一序列的延续性和标识符)
4)值对象:
定义:用来描述领域的特殊方面、且没有标示符的对象(只建议选择那些符合实体定义的对象作为实体,将剩下的对象处理成值对象)
优点:没有标识符,值对象可以被轻易创建或者丢弃,极大简化了设计
推荐:值对象保持不变,即他们由一个构造器创建,并且在它们的生命周期内永远不被修改
箴言:如果值对象时可共享的,它们应该是不可变的。(值对象应该保持尽量的简单)
注意:值对象可以包含其他的值对象,甚至可以包含对实体对象的引用
5)服务:
服务的3个特征:
a. 服务执行的操作涉及一个领域概念,这个领域概念通常不属于一个实体或者值对象
b. 被执行的操作涉及到领域中其它的对象
c. 操作时无状态的
推荐:最好显式声明服务,因为它创建了领域中一个清晰的特性,封装了一个概念
领域层服务和基础设施层服务:均建立在领域实体和值对象的上层,以便直接为这些相关的对象提供所需的服务;和谁相关,放到谁层
6)模块:
应该由在功能上或者逻辑上属于一体的元素组成,以保证内聚;具有定义好的接口,这些接口可以被其他模块访问
7)聚合:
用来定义对象所有权和边界的领域模式(针对数据变化可以考虑成一个单元的一组相关的对象)
每个聚合有一个根,这个根是一个实体,并且它是外部可以访问的唯一的对象(根可以保持对任意聚合对象的引用,并且其他对象可以持有任意其他的对象,但一个外部对象对能持有根对象的引用)。
根实体拥有全局的标识符,并且有责任管理不变量。内部的实体拥有内部的标识符。
8)工厂:
工厂用来封装对象创建所必需的知识(他们对创建聚合特别有用,当聚合的根建立时,所有聚合包含的对象将随之建立,所有的不变量得到强化)
不需要工厂的场景:
构造过程并不复杂;
对象的创建不涉及到其他对象的创建,所有的属性需要传递给构造函数;
客户程序对实现很感兴趣,可能希望选择使用策略模式;
类是特定类型,不涉及到继承,所以不用在一系列具体实现中进行选择。
9)资源库:
目的是封装所有获取对象引用所需要的逻辑
资源库的实现可能会非常类似于基础设施,但资源库的接口是纯粹的领域模型(或者是用规约Criteria指定查询条件)
资源库 VS 工厂:
工厂关注的是对象的创建,而资源库关心的是已经存在的对象;
资源库可能会在本地缓存对象,但更常见情况是从持久化存储中检索他们;
工厂创建新的对象,而资源库应该用来发现已经创建过的对象(新对象应该先由工厂创建,然后添加到资源库以便于将来保存它);
工厂是纯的领域,而资源库会包含对基础设施的连接,如数据库
4. 面向深层理解的重构:
重构是不改变应用行为而重新设计代码以让它更好的过程!(重构通常非常谨慎,按照小幅且可控的步骤进行,以不至于破坏功能或引入某些bug)
持续重构:所有的模型开始时都缺乏深度,但我们可以面向越来越深的理解来重构模型
规约应该被封装到一个负责它的对象中,这将成为客户的规约,并且被保留在领域层中
5. 保持模型一致性:
对于一个大型项目,不要试图保持一个迟早要四分五裂的大模型,应该做的是:有意识的将大模型分解成数个较小的部分(把相关联以及能形成一个自然概念的因素放在一个模型里,模型应该尽量小)。只要遵守相绑定的契约,整合得好的小模型会越来越有独立性。每个模型都应该有一个清晰的边界,模型之间关系也应该被精确地定义。
1)界定上下文
开发大的企业应用题时,需要为每一个我们创建的模型定义上下文(一旦界定的上下文被定义,我们就必须保持它的完整性)
持续集成式基于模型中概念的集成,然后再通过测试实现。(持续集成应用于界定的上下文,不会被用来处理相邻上下文之间的关系)
2)上下文映射:
指抽象出不同界定上下文和它们之间关系的文档。
3)共享内核:
共享内核的目的是减少重复,但是仍保持两个独立的上下文 (沟通 + 测试)
4)客户-供应商:
两个子系统之间的接口需要预先明确定义,另外还要创建一个统一的测试集,在任何接口需求被提出时用户测试
5)顺从者:
当不得不使用供应商的模型,并且不能对所提供模型做更改时,可以扮演顺从者。
可以创建一个适配器,在自己的模型和组建模型之间做转换,以隔离出自己的模型同时又很高的自由度去开发它
6)防崩溃层:
为了防止外部模型修改客户端模型,可建立防崩溃层
好的实现方案:将防崩溃层卡座从客户端模型来的一个服务(比作Facade),同时可能会用到Adapter。方案如下:

7)独立方法:
场景:适合一个企业应用可由几个较小的应用组成,而且从建模的角度来看彼此之间有很少或者没有相同之处的情况。
前提:需要明确的是不会回到集成系统,独立开发的模型是很难集成的
8)开放主机服务:
定义一个能以服务的形式访问你子系统的协议。开放它,使得所有需要和你集成的人都能获取到。然后优化和扩展这个协议,使其可以处理新的集成需求
9)精炼:
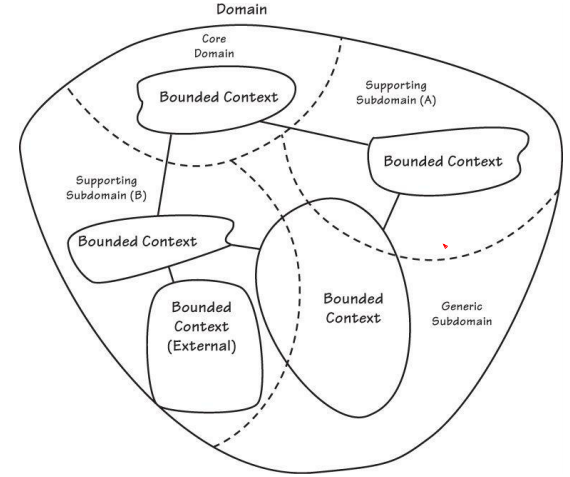
思路:定义一个代表领域本质的核心域(Core Domain)。精炼过程的副产品将是组合领域中其他部分的普通子域(Generic Subdomain)
方法:找到核心域,发现一个能轻松地从支持模型和代码中区分核心域的方法。强调最有价值和特殊的概念,使核心变小。