简介
什么是领域
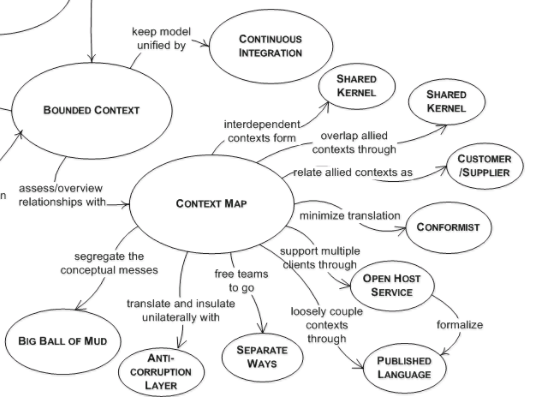
《领域驱动设计》书里写的是:用户会把软件程序应用于某个主体区域,这个区域就是软件的领域。简单来说,就认为是公司的某块业务好了。如果领域比较大,可以将其拆分为多个子域(Subdomain),子域包含核心域(Core Domain)和支撑子域(Supporting Subdomain),核心域顾名思义,是最重要的子域,我们应该把关注点集中在它上面;其余的子域都是支撑子域。支撑子域里有一类特殊的用于解决通用问题的子域,称为通用子域(Generic Subdomain),例如用户和权限等。不过这些都是相对而言的,对于消费方来说,他的支撑子域有可能就是你的核心域。个别子域可能会有交集,称为共享内核(Shared Kernel),目的是减少重复,但是仍保持两个独立的上下文。由于不同子域的开发团队可能会同时修改共享内核,所以需要小心并注意沟通
战术建模(Tactical Modeling)
模型
实体(Entity)
值对象(Value Object)
领域服务(Domain Service)
领域事件(Domain Event)
《领域驱动设计》一书出版之后,DDD社区并没有停止前进的步伐。领域事件就是在那之后提出来的。领域事件是一个定义了领域专家所关心的事件的对象。当关心的状态由于模型行为而发生改变时,系统将发布领域事件。如果通用语言里出现了:“当……的时候,需要……”通常就意味着一个领域事件。例如:当订单完成支付时,商品需要出库。这里的订单完成支付就预示着一个OrderPaidEvent,里面持有着这个订单的标识。领域事件代表的是已经发生的事,所以命名上通常都使用过去时(如Paid)。对领域事件的处理就像是一个观察者模式,由领域事件的订阅方来决定。订阅方既可以是本地的限界上下文,也可以是外部的限界上下文。
An event is something that has happened in the past. All events should be represented as verbs in the pas t tense such as CustomerRelocated, CargoShipped, or InventoryLossageRecorded. For those who speak French, it should be in Passé Composé, they are things that have completed in the past.
https://cqrs.files.wordpress.com/2010/11/cqrs_documents.pdf
生命周期
聚合(Aggregate)
聚合就是一组应该呆在一起的对象,聚合根(Aggregate Root)就是聚合在一起的基础,并提供对这个聚合的操作。聚合除了聚合根以外,还有自己的边界(boundary),即聚合里有什么。例如:一个订单可以有多个订单明细,订单明细不可能脱离订单而存在,而订单也不可能没有订单明细。这种情况下,订单和订单明细就是一个聚合,而订单就是这个聚合的聚合根,订单和订单明细就处于这个聚合的边界之内。如果要变更订单明细,我们需要通过操作聚合根订单来实现,如order.changeItemCount(),而非订单明细自身。另外一个例子:一名客户可以有多个订单,订单不可能脱离客户而存在,而客户却可以没有订单。这种情况下,客户和订单就是不同的两个聚合,一个聚合以客户为聚合根,另一个聚合以订单为聚合根,引用客户的标识。客户里并不引用订单的标识,这样将关联减至最少有助于简化对象的关系网。但是带来的一个麻烦就是如果要查找某位客户的所有订单,就不得不从所有的订单里查,而不能从客户这个聚合里直接获得。最后再举一个多对多的例子:一个班级可以有多名学生,学生可以脱离这个班级而存在,而班级不能没有学生,学生也不能不在班级里。这种情况下,班级和学生也是不同的两个聚合,一个聚合以班级为聚合根,引用学生的标识;另一个聚合以学生为聚合根,引用班级的标识,将多对多转换成两个一对多。
聚合是持久化的一个单位,我们需要保证以聚合为单位的数据一致性。如果聚合太大,那就会导致并发修改困难,多人并发修改同一个聚合里的不同项目,结果就是只有第一个提交的人成功修改,其它人不得不重新刷新聚合才能再次修改。大聚合还会导致性能问题,因为操作实体时会将整个大聚合同时加载进内存。珍爱生命,拒绝大聚合。
聚合根必须是实体而非值对象,因为它需要整体持久化,所以一定会有标识。而聚合根里的各个元素,既可能是实体,也可能是值对象。例如:一个订单(聚合根)一般会有订单明细(实体)和送货地址(值对象)。这些元素里可以有对聚合根的引用,但是不能相互引用。任何对其它元素的操作都必须通过聚合根来进行。聚合根里的标识是全局的,聚合根里的实体标识是聚合里唯一的本地标识,因为对它的访问都是通过聚合根来操作的。聚合根拥有自己独立的生命周期,其实体的生命周期从属于其所属的聚合,值对象因为只是值而已,并没有生命周期。
例子
https://github.com/dotnet-architecture/eShopOnContainers/tree/dev/src/Services/Ordering/Ordering.Domain/AggregatesModel
订单有2个聚合根,BuyerAggregate和OrderAggregate
资源库(Repository)
Domain Events vs. Integration Events in Domain-Driven Design and microservices architectures
Domain Events
That mentioned difference is really important because in the first model (pure Domain Events) you must do everything in-process (in-memory) and within the same transaction or operation. You have to raise the event from a business method in a Domain Entity class (An AggregateRoot or a Child Domain Entity) and handle the event from multiple handlers (anyone subscribed) but all happening within the same transaction scope. That is critical because if when publishing a domain event, that event was published asynchronously in a “fire and forget” way to somewhere else, including the possibility of remote systems, that event propagation would have occurred before committing your original transaction, therefore, if your original transaction or operation fails, you will have inconsistent data between your original local domain and the subscribed systems (potentially, out-of-process, like another microservice).
However, if those events are handled only within the same transaction scope and in-memory, then, the approach is good and provides a “fully encapsulated Domain Model”.
In short, in-memory Domain events and their side effects (event handler’s operations) need to occur within the same logical transaction.
Integration Events
Dealing with integration events is usually a different matter than using domain events within the same transaction. You might need to send asynchronous events to communicate and propagate changes from one original domain model (the original microservice or original bounded-context, for instance) to multiple subscribed microservices or even external subscribed applications.
Because of that asynchronous communication, you should not publish integration events until you are 100% sure that your original operation, the event, really happened in the past. That means it was persisted in a database or any durable system. If you don’t do that, you can end up with inconsistent information across multiple microservices, bounded-contexts or external applications.
This kind of Integration Event is pretty similar to the events used in a full CQRS with a different “reads-database” than the “writes-database” and you need to propagate changes/events from the transactional or “writes-database” to the “reads-database”.
A very similar scenario would be when communicating out-of-process microservices, each microservice owning its own model, as it is really the same pattern, as well.
Therefore, when you publish an integration event you usually would do it from the infrastructure layer or the application layer, right after saving the data to the persistent database, for instance, Greg Young does it that way in his simplified CQRS+EventSource example: