一、简单动态字符串SDS
struct sdshdr {
int len;
int free;
char[] buf;
}简单字符串结构被用于存储redis的key对象和String类型的value对象

其中的free和len字段可以轻松的使得在该字符串被修改时判断是否需要扩容。
为啥呢?因为redis的协议发送一个SET请求时格式开头会带上需要插入的value的长度,这样根据free以及len可以判断此时redis分配的数组大小是多少,需不需要扩容。对比于C语言的O(n)复杂度计算数组长度更快。
扩容策略:如果字符串大小<1MB, 每次扩容为2n+1大小;如果大于1MB,每次扩容1MB。
二、链表
链表结构用于存储list类型的键值(类似index),还有发布订阅等功能也用了链表结构。
链表节点:ListNode
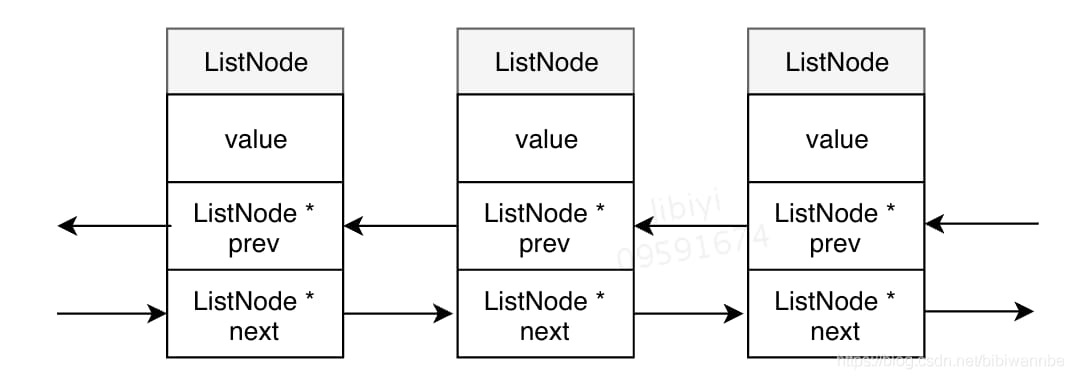
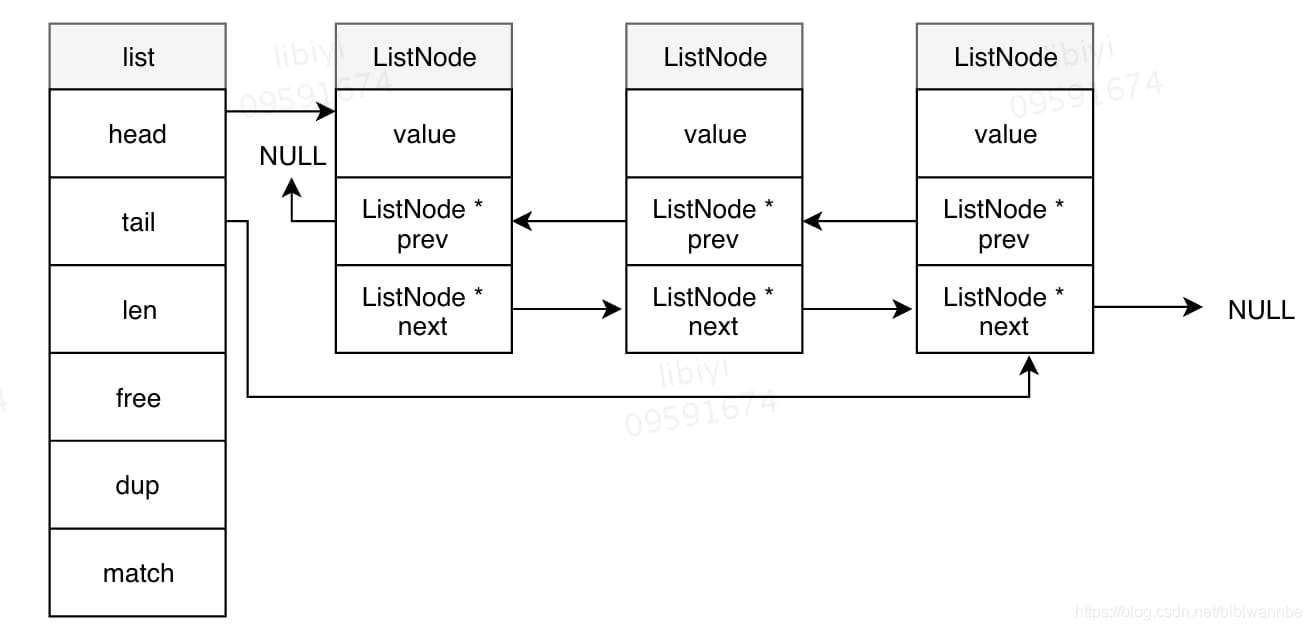
链表:list
代码块
typedef struct list{
ListNode * tail;
ListNode * head;
unsigned long len;
//节点值复制方法
void *(*dup) (void * ptr);
//节点值释放方法
void *(*free) (void * ptr);
//节点值对比方法
int (*match)(void * ptr, void * key);
}list+ListNode的链表结构
三、字典
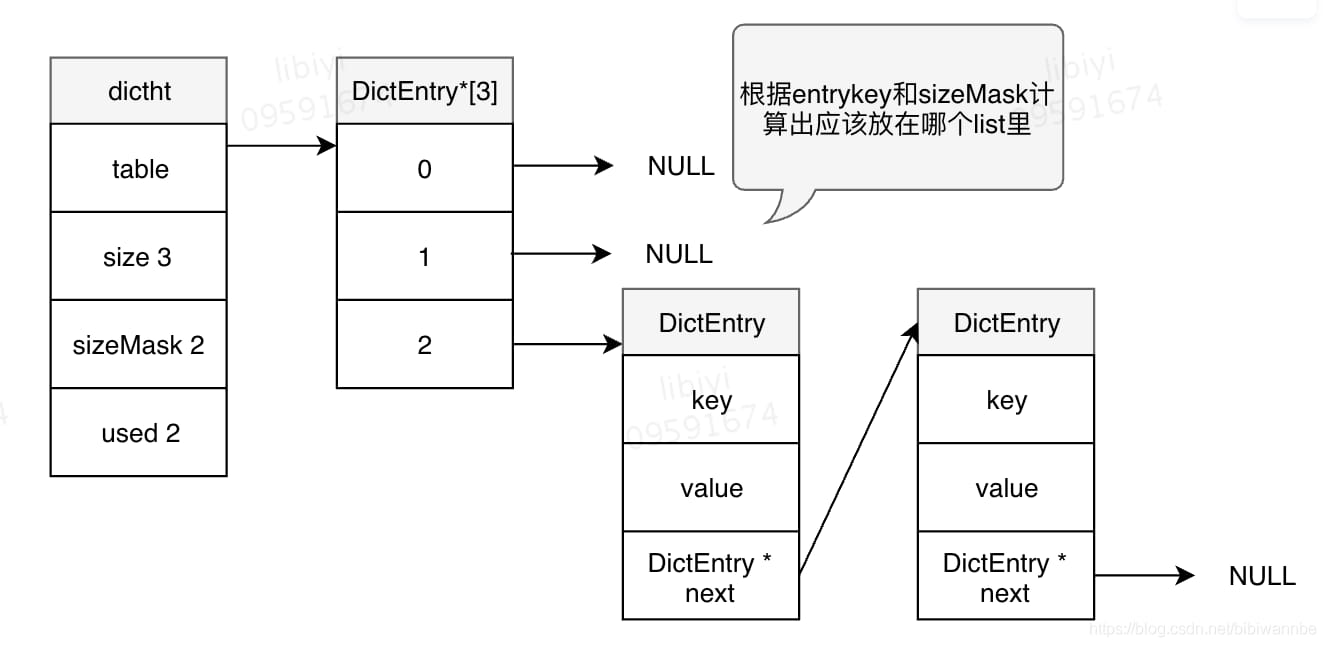
哈希表的结构:
字典的结构:
typedef struct dict{
dictType *type;
void *privdata;
dictht *ht[2];
int rehashIndx;
}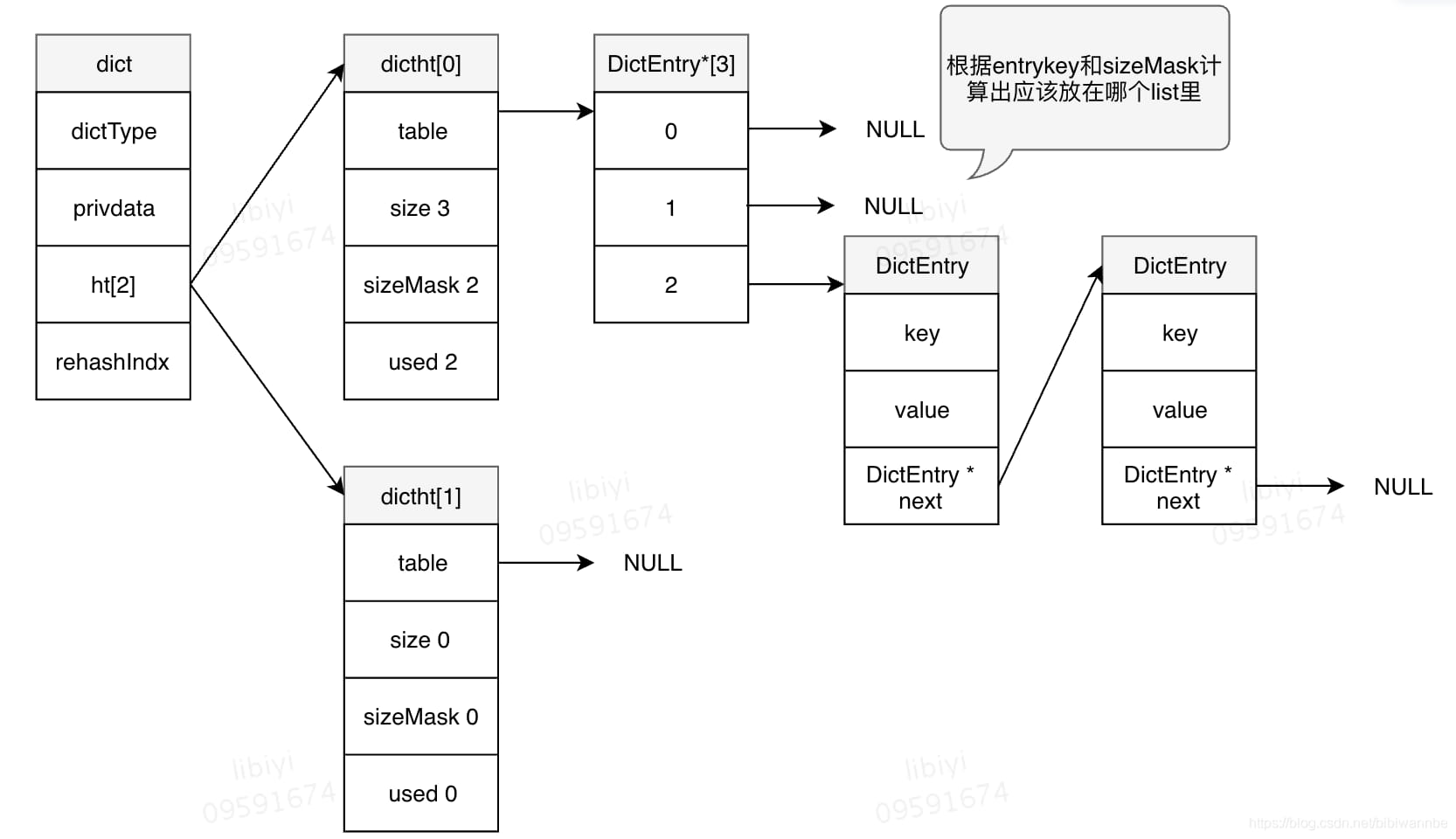
ht[2]: 需要两个hashTable的原因是在进行rehash的操作时,需要使用另一个hashTable。
rehashIndx:在不进行rehash时值为-1,在渐进rehash过程中,这个值代表了rehash进行到的dictEntry的索引。
在hash时将会根据key取哈希&sizeMark来获得dictEnrty数组的下标索引,当数组中非空则将dictEntry元素插入到链表第一个位置。
随着链表的长度越来越长,对于字典的查询速度也会越慢,这时候就需要rehash。
rehash将会用到另一个空哈希表ht[1],将里面的table数组大小增加,再将原来的键值重新hash放入新的DictEntry中。rehash完毕后,把ht[1]变为ht[0], 再重新开辟一个空间作为ht[1]。
四、跳跃表
跳跃表用作有序集合键的底层实现以及在集群节点用作内部数据结构
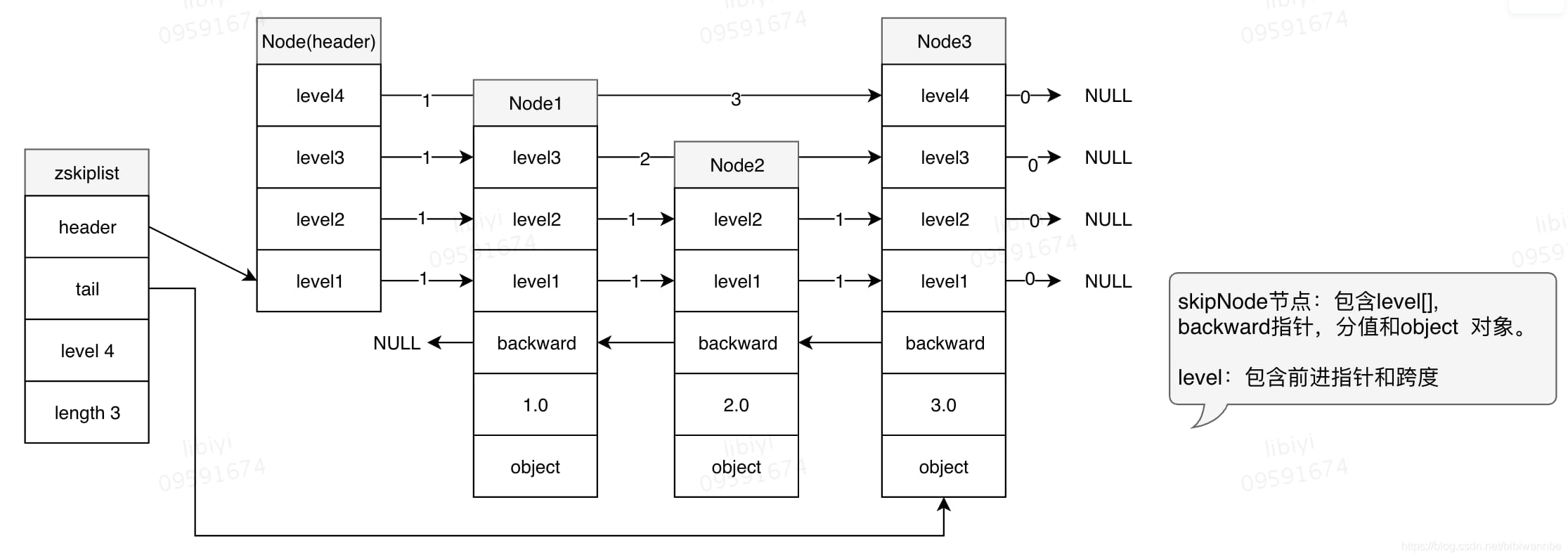
后退指针:后退指针用于从表尾遍历节点。
object:保存的是一个指向对象的指针。
score分值:关乎节点的排序,如果分值相同则成员对象较大的排在后面。
zskiplist:虽然通过多个节点就可以组成跳跃表,但是使用zskiplist中的length、level字段就可以在O(1)复杂度返回跳跃表的长度以及层级。
五、整数集合

encoding:可支持存储INSET_ENC_INT16、INSET_ENC_INT32、INSET_ENC_INT64(int16_t、int32_t、int64_t)三种位数的整数。
content: 在这个数组中按照大小顺序存放整数,并且元素不会出现重复项。
集合升级:当集合需要插入一个比原有类型更大的整数时,需要先给数组的每个元素重新分配空间,首先先扩大数组空间到相应的大小,再将原来位置上的整数从后往前重新进行类型转换放到相应的索引上。每次升级都需要对底层元素进行转型并移动,时间复杂度为O(N)。升级使得这个集合更为节省内存,并且可以使得使用者不必关注c语言底层创建数组时指定类型位数不足而导致的插入异常问题。
整数集合不支持降级。
六、压缩列表
压缩列表是列表建和哈希键底层实现之一。一个列表键只包含少量列表项,并且每个列表项要么就是整数值,要么就是长度比较短的字符串,Redis就会使用压缩列表来做列表键的底层实现。

zlbytes:记录整个压缩列表占用的内存字节数,对压缩列表进行内存重分配、计算zlend位置时使用。
zltail:记录压缩列表表尾节点距离压缩列表起始地址有多少字节;通过这个偏移量,程序无序遍历整个压缩列表就可以确定表尾节点地址。
zzllen:压缩列表节点数量;当这个值等于UINT16_MAX时,节点的真实数量需要遍历整个压缩列表才能计算得出。
entryX:列表节点,压缩列表包含的各个节点,节点长度由节点保存的内容决定
zlend:特殊值0xFF记录标记压缩列表的末端。
压缩列表节点

previous_entry_length:记录前一个压缩列表节点的长度,可通过这个属性减去指针起始地址往前回溯节点,该属性的长度为1字节或5字节,当前一节长度小于254字节,则前一节长度使用这个字段直接保存,如果前一节长度>=254字节,则前一字节设置为0xFE,之后四个字节用十进制保存长度。
encoding:记录了节点content属性保存的数据类型及长度。
content:保存节点值,可以是字节数组或者整数("hello world"、10086)
连锁更新机制:由于在进行节点插入时,一旦节点长度>=254字节,则修改后续节点的previos_entry_length属性,从1字节扩至5字节,可能再次引起后续节点的连锁修改。
就需要对压缩列表的执行空间重新分配,对每个节点进行重新分配需要的复杂度为O(N),则最坏需要进行N次分配,则连锁更新最坏复杂度为O(N2)。
到此这篇关于浅谈一下Redis的数据结构的文章就介绍到这了,更多相关Redis的数据结构内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!