正则表达式基础(Regular Expression)
正则表达式简介
n 为什么需要正则表达式?
q 文本的复杂处理。
n 正则表达式的优势和用途?
q 一种强大而灵活的文本处理工具;
q 提供了一种紧凑的、动态的方式,能够以一种完全通用的方式来解决各种字符串处理(例如:验证、查找、替换等)问题;
q 大部分语言、数据库都支持正则表达式。
n 正则表达式定义:
q 正如他的名字一样是描述了一个规则,通过这个规则可以匹配一类字符串。
n 正则表达式的用处:
q 验证给定字符串是否符合指定特征,比如验证是否是合法的邮件地址。
q 用来查找字符串,从一个长的文本中查找符合指定特征的字符串。
q 用来替换,比普通的替换更强大
工具软件RegexBuddy的使用
n 为了提高开发效率,一般都先在工具软件中测试正则表达式,通过测试后,才在程序中使用。
正则表达式规则
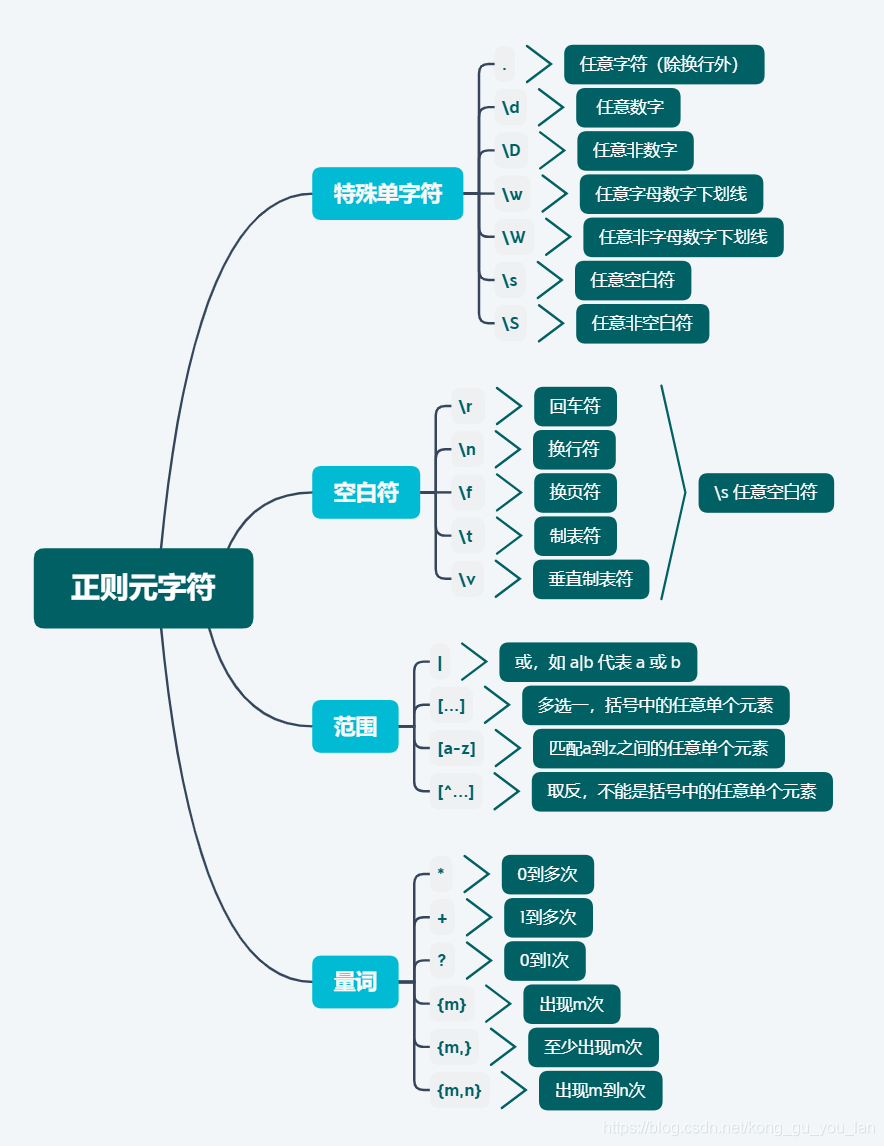
n 普通字符
q 字母、数字、汉字、下划线、以及没有特殊定义的标点符号,都是“普通字符”。表达式中的普通字符,在匹配一个字符串的时候,匹配与之相同的一个字符。
n 简单的转义字符
|
\n |
代表换行符 |
|
\t |
制表符 |
|
\\ |
代表\本身 |
|
\^ ,\$,\.,\(, \) , \{, \} , \? , \+ , \* , \| ,\[, \] |
匹配这些字符本身 |
n 标准字符集合:能够与 ‘多种字符’ 匹配的表达式
q (注意区分大小写,大写是相反的意思)
|
\d |
任意一个数字,0~9 中的任意一个 |
|
\w |
任意一个字母或数字或下划线,也就是 A~Z,a~z,0~9,_ 中任意一个 |
|
\s |
包括空格、制表符、换行符等空白字符的其中任意一个 |
|
. |
小数点可以匹配除了换行符(\n)以外的任意一个字符 |
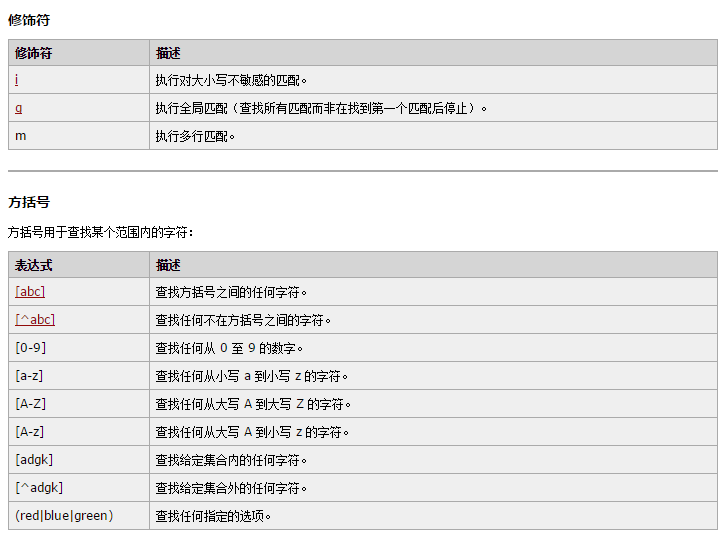
n 自定义字符集合:[ ]方括号匹配方式,能够匹配方括号中任意一个字符
|
[ab5@] |
匹配 "a" 或 "b" 或 "5" 或 "@" |
|
[^abc] |
匹配 "a","b","c" 之外的任意一个字符 |
|
[f-k] |
匹配 "f"~"k" 之间的任意一个字母 |
|
[^A-F0-3] |
匹配 "A"~"F","0"~"3" 之外的任意一个字符 |
注意事项:
1. 正则表达式中的特殊符号,如果被包含于中括号中,则失去特殊意义,但 \ [ ] : ^ - 除外。
2. 标准字符集合,除小数点(.)外,如果被包含于中括号中,自定义字符集合将包含该集合。
比如:[\d.\-+],将可以匹配数字,小数点和 + - 符号。(小数点和 + 号失去特殊意义)
n 修饰匹配次数的特殊符号
|
{n} |
表达式重复n次 |
|
{m,n} |
表达式至少重复m次,最多重复n次 |
|
{m,} |
表达式至少重复m次 |
|
? |
匹配表达式0次或者1次,相当于 {0,1} |
|
+ |
表达式至少出现1次,相当于 {1,} |
|
* |
表达式不出现或出现任意次,相当于 {0,} |
n 匹配次数中的贪婪模式(匹配字符越多越好)
q “{m,n}”, “{m,}”, “?”, “*”, “+”,具体匹配的次数随被匹配的字符串而定。这种重复匹配不定次数的表达式在匹配过程中,总是尽可能多的匹配。
n 匹配次数中的非贪婪模式(匹配字符越少越好)
q 在修饰匹配次数的特殊符号后再加上一个 "?" 号,则可以使匹配次数不定的表达式尽可能少的匹配,使可匹配可不匹配的表达式,尽可能的 "不匹配"。
n 字符边界(本组标记匹配的不是字符而是位置,符合某种条件的位置)
|
^ |
与字符串开始的地方匹配 |
|
$ |
与字符串结束的地方匹配 |
|
\b |
匹配一个单词边界 |
n 选择符和分组
|
表达式 |
作用 |
|
| |
左右两边表达式之间 "或" 关系,匹配左边或者右边 |
|
( ) |
(1). 在被修饰匹配次数的时候,括号中的表达式可以作为整体被修饰 (2). 取匹配结果的时候,括号中的表达式匹配到的内容可以被单独得到 (3). 每一对括号会分配一个编号,使用 () 的捕获根据左括号的顺序从 1 开始自动编号。捕获元素编号为零的第一个捕获是由整个正则表达式模式匹配的文本 |
n 反向引用(\nnn)
q 每一对()会分配一个编号,使用 () 的捕获根据左括号的顺序从 1 开始自动编号。
q 通过反向引用,可以对分组已捕获的字符串进行引用。
n 非捕获组(?:xxx)
q 与捕获组的区别在于不捕获匹配的文本,仅仅作为分组。其他地方一致。
n 模式修改符 (?ismg)*****(?-ismg) (用的不多,听听就行!)
q 在正则表达式中间,对匹配模式进行修改。
大小写模式修改,比如匹配a,A:
- [aA]
- 把整个模式修改为大小写不敏感。
- (?i)a(?-i)
n 预搜索(零宽断言)
q 判断当前位置的前后字符,是否符合指定的条件,但不匹配前后的字符。是对位置的匹配。
|
(?=exp) |
断言自身出现的位置的后面能匹配表达式exp |
|
(?<=exp) |
断言自身出现的位置的前面能匹配表达式exp |
|
(?!exp) |
断言此位置的后面不能匹配表达式exp |
|
(?<!exp) |
断言此位置的前面不能匹配表达式exp |
正则表达式的匹配模式
n IGNORECASE 忽略大小写模式
q 匹配时忽略大小写。
q 默认情况下,正则表达式是要区分大小写的。
n SINGLELINE 单行模式
q 整个文本看作一个字符串,只有一个开头,一个结尾。
q 使小数点 "." 可以匹配包含换行符(\n)在内的任意字符。
n MULTILINE 多行模式
q 每行都是一个字符串,都有开头和结尾。
q 在指定了 MULTILINE 之后,如果需要仅匹配字符串开始和结束位置,可以使用 \A 和 \Z
开发中使用正则表达式的流程
- 分析所要匹配的数据,写出测试用的典型数据
- 在工具软件中进行匹配测试
- 在程序中调用通过测试的正则表达式
课堂练习
n 电话号码验证
q (1)电话号码由数字和"-"构成
q (2)电话号码为7到8位
q (3)如果电话号码中包含有区号,那么区号为三位或四位, 首位是0.
q (4)区号用"-"和其他部分隔开
q (5)移动电话号码为11位
q (6)11位移动电话号码的第一位和第二位为"13“,”15”,”18”
n 电子邮件地址验证
1.用户名:字母、数字、中划线、下划线组成。
2.@
3.网址:字母、数字组成。
4. 小数点:.
5. 组织域名:2-4位字母组成。
6.不区分大小写。
[a-zA-Z0-9_\-]+@[A-Za-z0-9]+(\.[a-zA-Z]{2,3}){1,2}
使用模式修改符:(?i)[a-z0-9_\-]+@[a-z0-9]+(\.[a-z]{2,3}){1,2}(?-i)