正则表达式:专门用来描述字符串中字符出现规则的表达式。
简写:
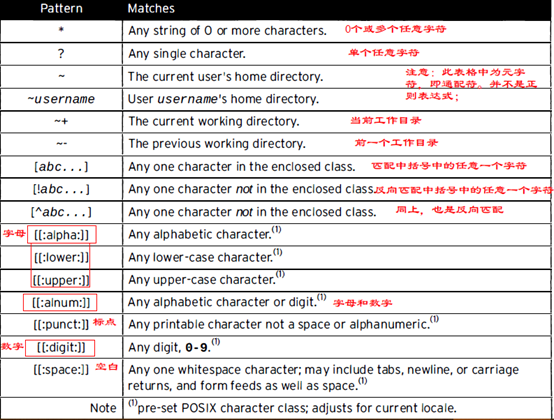
匹配一位小写字母:[a-z],共26个。
匹配一位大写字母:[A-Z],共26个。
要匹配一位字母:[A-Za-z],共52个。
要匹配一位字母或数字:[0-9A-Za-z],共62个。
要匹配一位汉字:[\u4e00-\u9fa5]。

预定义字符集:
正则表达式为四种最常用的字符集定义了最简化写法,称为预定义字符集。
包括:
要匹配一位数字:\d 等效于 [0-9]
要匹配一位字母、数字或_:\w 等效于 [0-9A-Za-z_]
要匹配一位空字符:\s 可匹配 空格、制表符Tab等空白
要匹配所有文字(通配符):.
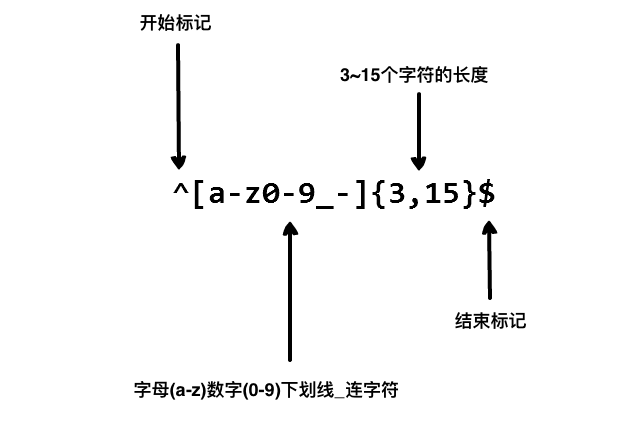
匹配手机号规则简写为:1[3-8]\d\d\d\d\d\d\d\d\d
数量词:紧跟在修饰的字符集之后,默认修饰相邻的前一个字符集
比如:手机号中连续出现的9个数字\d,可简写为:
1[3-8]\d{9}
指定匹配位置:
比如:匹配一组连续的空字符
1、匹配任意一组连续的空字符:\s+
2、仅匹配开头的空字符:^\s+
3、仅匹配结尾的空字符:\s+$
4、同时匹配开头和结尾的空字符:^\s+|\s+$
使用indexOf查找敏感词的位置
var i=str.indexOf("要找的敏感词")
返回值:
1). 如果找到敏感词,返回"敏感词"第一个字在字符串中所在位置的下标
2). 如果找不到,返回-1
案例:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script>
// indexOf查找敏感词
// 请用户输入一条消息
var msg = prompt('请输入消息内容');
var i = msg.indexOf('我草');
// 如果找到,返回我草在字符串中的下标位置
// 如果没找到,返回-1
// 返回值不是-1,说明找到了敏感词
if(i != -1){
document.write(`<h1 style="color:red">发现敏感词,禁止发送</h1>`)
}else{
document.write(`</h1>${msg}</h1>`)
}
</script>
</body>
</html>
用正则表达式模糊查找多种敏感词的出现的位置:
var i=str.search(/正则/i)
查找聊天记录中微信敏感词及其变种:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script>
// search查找敏感词
// 请用户输入一条消息
var msg = prompt('请输入消息内容');
// 微信的正则:
// 第一个字:微或wei,其中ei可有可无,最多一次——(微|w(ei)?)
// 第一个字和第二个字之间可能有或者没有不确定数量的空字符——\s*
// 第二个字:信或xin,其中in可有可无,最多一次——(信|x(in)?)
var i = msg.search(/(微|w(ei)?)\s*(信|x(in)?)/i);
if(i != -1){
document.write(`<h1 style="color:red">发现敏感词,禁止发送</h1>`)
}else{
document.write(`</h1>${msg}</h1>`)
}
</script>
</body>
</html>
缺点:使用search查找无法知道查找的敏感词内容
使用match查找敏感词的位置和内容
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script>
// match查找敏感词
// 请用户输入一条消息
var msg = prompt('请输入消息内容');
// 微信的正则:
// 第一个字:微或wei,其中ei可有可无,最多一次——(微|w(ei)?)
// 第一个字和第二个字之间可能有或者没有不确定数量的空字符——\s*
// 第二个字:信或xin,其中in可有可无,最多一次——(信|x(in)?)
var arr = msg.match(/(微|w(ei)?)\s*(信|x(in)?)/i);
if(arr != null){
document.write(`<h1 style="color:red">在位置${arr['index']}处发现敏感词${arr[0]},禁止发送</h1>`)
}else{
document.write(`</h1>${msg}</h1>`)
}
</script>
</body>
</html>
正则表达式默认只匹配一个关键词,如果找到,就不再继续查找。
解决办法:在/后加g,表示全局匹配。
问题:如果match加g,就只能返回敏感词的内容,无法返回位置了。
如果没找到,返回null。