匹配符:
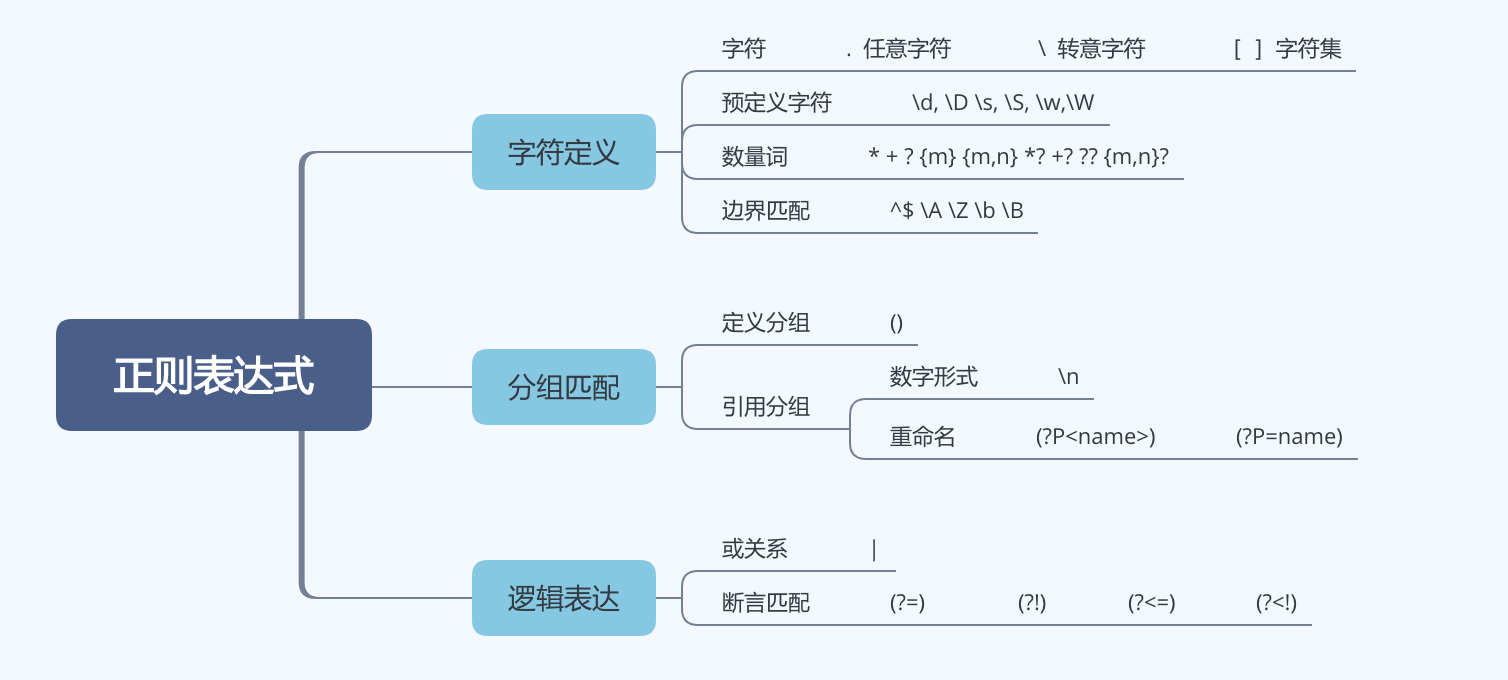
^ 匹配字符串开始位置。在多行字符串模式匹配每一行的开头。
$ 匹配字符串结束位置。在多行字符串模式匹配每一行的结尾。
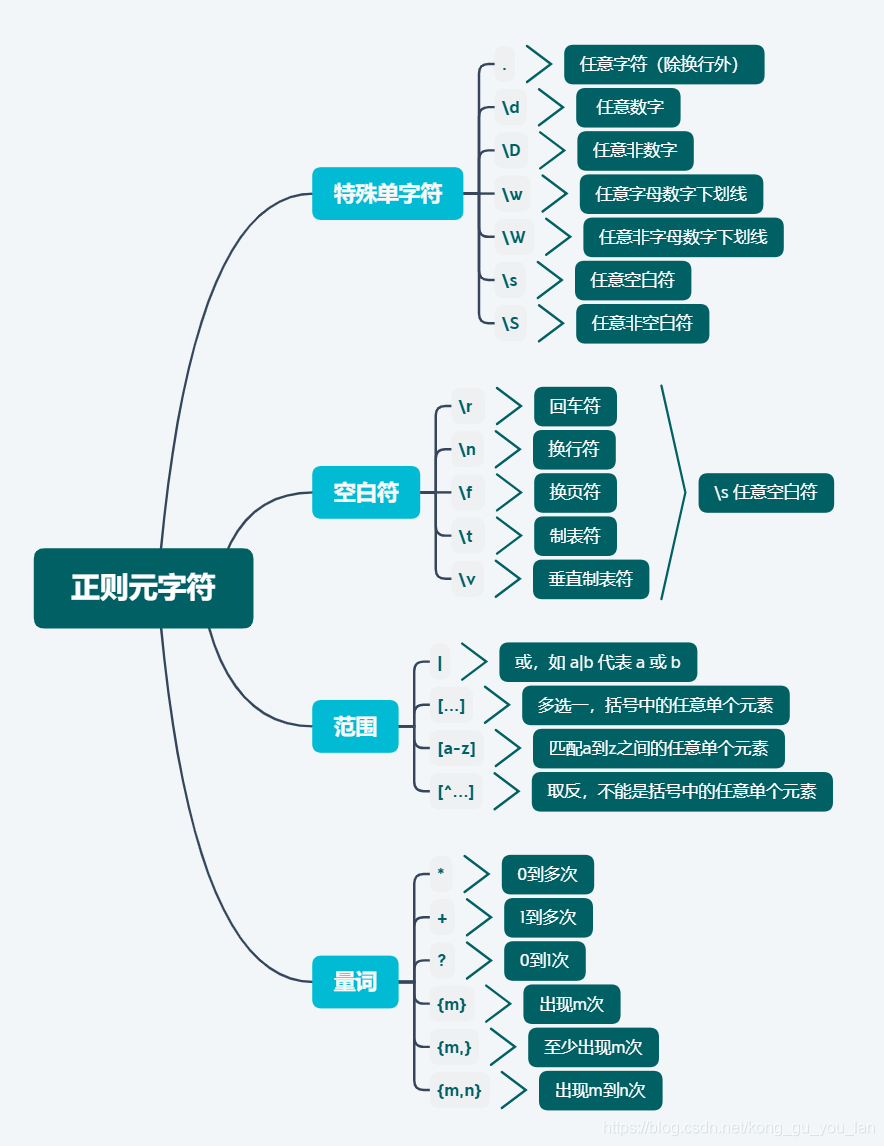
. 匹配除了换行符外的任何字符,在 alternate 模式(re.DOTALL)下它甚至可以匹配换行。
\A 匹配字符串开头
\Z 匹配字符串结尾
\b 匹配一个单词边界。即 \w 与 \W 之间。
\B 匹配一个非单词边界;相当于类 [^\b]。
\d 匹配一个数字。
\D 匹配一个任意的非数字字符。
\s 匹配任何空白字符;它相当于类 [
\r\f\v]。
\S 匹配任何非空白字符;它相当于类 [^
\r\f\v]。
\w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。
\W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]。
x? 匹配可选的x字符。即是0个或者1个x字符。
x* 匹配0个或更多的x。
x+ 匹配1个或者更多x。
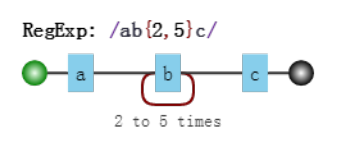
x{n,m} 匹配n到m个x,至少n个,不能超过m个。
(a|b|c) 匹配单独的任意一个a或者b或者c。
(x) 捕获组,小括号括起来即可,它会记忆它匹配到的字符串。
可以用 re.search() 返回的匹配对象的 groups()函数来获取到匹配的值。
\1 记忆组,它表示记住的第一个分组;如果有超过一个的记忆分组,可以使用 \2 和 \3等等。
记忆组的内容也要小括号括起来。
(?iLmsux) iLmsux的每个字符代表一种匹配模式
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
re.M(re.MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
re.S(re.DOTALL): 点任意匹配模式,改变'.'的行为
re.L(re.LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
re.U(re.UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
re.X(re.VERBOSE): 松散正则表达式模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
(?:表达式) 无捕获组。与捕获组表现一样,只是没有内容。
(?P表达式) 命名组。与记忆组一样,只是多了个名称。
(?P=name) 命名组的逆向引用。
(?#...) “#”后面的将会作为注释而忽略掉。例如:“ab(?#comment)cd”匹配“abcd”
(?=...) 之后的字符串需要匹配表达式才能成功匹配。不消耗字符串内容。例:“a(?=\d)”匹配“a12”中的“a”
(?!...) 之后的字符串需要不匹配表达式才能成功匹配。不消耗字符串内容。例:“a(?!\d)”匹配“abc”中的“a”
(?<=...) 之前的字符串需要匹配表达式才能成功匹配。不消耗字符串内容。例:“(?<=\d)a”匹配“2a”中的“a”
(?<!...) 之前的字符串需要不匹配表达式才能成功匹配。不消耗字符串内容。例:“(?<!\d)a”匹配“sa”中的“a”
注:上面4个表达式的里面匹配的内容只能是一个字符,多个则报错。
(?(id/name)yes-pattern|no-pattern) 如果编号为 id 或者别名为 name 的组匹配到字符串,
则需要匹配yes-pattern,否则需要匹配no-pattern。 “|no-pattern”可以省略。如:“(\d)ab(?(1)\d|c)”匹配到“1ab2”和“abc“
# 必须引入 re 标准库
import re
# 字符串替换: sub() 与 subn()
s='100 NORTH MAIN ROAD'
# 将字符串结尾的单词“ROAD”替换成“RD.”;该 re.sub() 函数执行基于正则表达式的字符串替换。
print(re.sub(r'\bROAD$', 'RD.', s)) # 打印: 100 NORTH MAIN RD.
## subn() 与 sub() 作用一样,但返回的是包含新字符串和替换执行次数的两元组。
print(re.subn(r'\bROAD$', 'RD.', s)) # 打印: ('100 NORTH MAIN RD.', 1)
# 字符串分割, split()
# 在正则表达式匹配的地方将字符串分片,将返回列表。只支持空白符和固定字符串。可指定最大分割次数,不指定将全部分割。
print(re.split(r'\s+', 'this is a test')) # 打印: ['this', 'is', 'a', 'test']
print(re.split(r'\W+', 'This is a test.', 2)) # 指定分割次数,打印:['this', 'is', 'a test']
# 如果你不仅对定界符之间的文本感兴趣,也需要知道定界符是什么。在 RE 中使用捕获括号,就会同时传回他们的值。
print(re.split(r'(\W+)', 'This is a test.', 2)) # 捕获定界符,打印:['this', ' ', 'is', ' ', 'a test']
## `MatchObject` 实例的几个方法
r=re.search(r'\bR(OA)(D)\b', s)
print(rs()) # 返回一个包含字符串的元组,可用下标取元组的内容,打印: ('OA', 'D')
print(r()) # 返回正则表达式匹配的字符串,打印: ROAD
print(r(2)) # 返回捕获组对应的内容(用数字指明第几个捕获组),打印: D
print(r.start()) # 返回匹配字符串开始的索引, 打印: 15
print(r.end()) # 返回匹配字符串结束的索引,打印: 19
print(r.span()) # 返回一个元组包含匹配字符串 (开始,结束) 的索引,打印: (15, 19)
# 匹配多个内容, findall() 返回一个匹配字符串行表
p=repile('\d+')
s0='12 drummers drumming, 11 pipers piping, 10 lords a-leaping'
print(p.findall(s0)) # 打印: [12, 11, 10]
print(re.findall(r'\d+', s0)) # 也可这样写,打印: [12, 11, 10]
# 匹配多个内容, finditer() 以迭代器返回
iterator=p.finditer(s0)
# iterator=re.finditer(r'\d+', s0) # 上句也可以这样写
for match in iterator:
print(match()) # 三次分别打印:12、 11、 10
# 记忆组
print(re.sub('([^aeiou])y$', 'ies', 'vacancy')) # 将匹配的最后两个字母替换掉,打印: vacanies
print(re.sub('([^aeiou])y$', r'\1ies', 'vacancy')) # 将匹配的最后一个字母替换掉,记忆住前一个(小括号那部分),打印: vacancies
print(re.search('([^aeiou])y$', 'vacancy')(1)) # 使用 group() 函数获取对应的记忆组内容,打印: c
# 记忆组(匹配重复字符串)
p=repile(r'(?P\b\w+)\s+\1') # 注意, re.match() 函数不能这样用,会返回 None
p=p.search('Paris in the the spring')
# p=re.search(r'(?P\b\w+)\s+\1', 'Paris in the the spring') # 这一句可以替换上面两句
print(p()) # 返回正则表达式匹配的所有内容,打印: the the
print(ps()) # 返回一个包含字符串的元组,打印: ('the',)
# 捕获组
r=re.search(r'\bR(OA)(D)\b', s) # 如过能匹配到,返回一个 SRE_Match 类(正则表达式匹配对象);匹配不到则返回“None”
# `MatchObject` 实例的几个方法
if r: # 如果匹配不到,则 r 为 None,直接执行下面语句则会报错;这里先判断一下,避免这错误
print(rs()) # 返回一个包含字符串的元组,可用下标取元组的内容,打印: ('OA', 'D')
print(r()) # 返回正则表达式匹配的字符串,打印: ROAD
print(r(2)) # 返回捕获组对应的内容(用数字指明第几个捕获组),打印: D
# 无捕获组
print(re.match("([abc])+", "abcdefab")s()) # 正常捕获的结果: ('c',)
print(re.match("(?:[abc])+", "abcdefab")s()) # 无捕获组的结果: ()
# 命名组
m=re.match(r'(?P\b\w+\b) *(?P\b\w+\b)', 'Lots of punctuation')
print(ms()) # 返回正则表达式匹配的所有内容,打印:('Lots', 'of')
print(m(1)) # 通过数字得到对应组的信息,打印: Lots
print(m('word2')) # 通过名称得到对应组的信息,打印: of
# 命名组 逆向引用
p=repile(r'(?P\b\w+)\s+(?P=word)') # 与记忆组一样用法, re.match() 函数同样不能这样用,会返回 None
p=p.search('Paris in the the spring') # r'(?P\b\w+)\s+(?P=word)' 与 r'(?P\b\w+)\s+\1' 效果一样
print(p()) # 返回正则表达式匹配的所有内容,打印: the the
print(ps()) # 返回一个包含字符串的元组,打印: ('the',)
# 使用松散正则表达式,以判断罗马数字为例
pattern='''
^ # beginning of string
(M{0,3}) # thousands - 0 to 3 Ms
(CM|CD|D?C{0,3}) # hundreds - 900 (CM), 400 (CD), 0-300 (0 to 3 Cs),
# or 500-800 (D, followed by 0 to 3 Cs)
(XC|XL|L?X{0,3}) # tens - 90 (XC), 40 (XL), 0-30 (0 to 3 Xs),
# or 50-80 (L, followed by 0 to 3 Xs)
(IX|IV|V?I{0,3}) # ones - 9 (IX), 4 (IV), 0-3 (0 to 3 Is),
# or 5-8 (V, followed by 0 to 3 Is)
$ # end of string
'''
print(re.search(pattern, 'M')) # 这个没有申明为松散正则表达式,按普通的来处理了,打印: None
print(re.search(pattern, 'M', re.VERBOSE)s()) # 打印: ('M', '', '', '')
# (?iLmsux) 用法
# 以下这三句的写法都是一样的效果,表示忽略大小写,打印: ['aa', 'AA']
print(re.findall(r'(?i)(aa)', 'aa kkAAK s'))
print(re.findall(r'(aa)', 'aa kkAAK s', re.I))
print(re.findall(r'(aa)', 'aa kkAAK s', re.IGNORECASE))
# 可以多种模式同时生效
print(re.findall(r'(?im)(aa)', 'aa kkAAK s')) # 直接在正则表达式里面写
print(re.findall(r'(aa)', 'aa kkAAK s', re.I | re.M)) # 在参数里面写
print(re.findall(r'(aa)', 'aa kkAAK s', re.I or re.M))
# 预编译正则表达式解析的写法
# romPattern=repile(pattern) # 如果不是松散正则表达式,则这样写,即少写 re.VERBOSE 参数
romPattern=repile(pattern, re.VERBOSE)
print(romPattern.search('MCMLXXXIX')s()) # 打印: ('M', 'CM', 'LXXX', 'IX')
print(romPattern.search('MMMDCCCLXXXVIII')s()) # 打印: ('MMM', 'DCCC', 'LXXX', 'VIII')
# match()、search()、sub()、findall() 等等都可以这样用