正则表达式 导入模块
import retext = r "rubyrjavamatlabpythonhtmlc++ "
p = r "python "
pat =
正则表达式
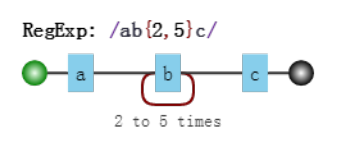
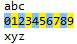
#导入模块 import re text = r"rubyrjavamatlabpythonhtmlc++" p = r"python" pat = re.compile(p) mat = re.search(pat, text) print(mat.group(0)) #说明,符号“.”代表匹配包括本身在内的任何一个字符,“+”表示将前面的一个字符或者表达式重复一次或者多次,至少有一次 #下例中如果p1改为r"<test>.<test>",那么得到的匹配结果为空 #findall返回所有符合要求的列表 text1 = r"<test>python<test>" p1 = r"<test>.+<test>" pat1 = re.compile(p1) print('1:', pat1.findall(text1)) #如果想要匹配“.”本身,那么需要借助转义符“\” #下例中其实不加“\”也能得到正确的结果,因为“.”可以匹配任意一个字符,包括它本身 text2 = r"http://www.baidu.com/" p2 = r"www\.baidu\.com" pat2 = re.compile(p2) print('2:', pat2.findall(text2)) #符号“+”将前面一个字符或者子表达式重复一遍或者多遍,符号“*”匹配前面0次或者多次 #比较以下结果,前一个不能够完成匹配,后一个可以匹配到python text3 = r"rubypythonpythonmatlab" p3 = r"pythonn+" pat3 = re.compile(p3) print('3:', pat3.findall(text3)) text4 = r"rubypythonmatlab" p4 = r"pythonn*" pat4 = re.compile(p4) print('4:', pat4.findall(text4)) #[]表示匹配里面的任意一个字符 text5 = r"aython bython cython python" p5 = r"[pth]ython" pat5 = re.compile(p5) print('5:', pat5.findall(text5)) #[^]表示除了里面的字符以外都匹配 text6 = r"aython bython cython python" p6 = r"[^p]ython" pat6 = re.compile(p6) print('6:', pat6.findall(text6)) #贪婪的和懒惰的“+” #原意想得到'http://www.'的匹配结果,但是得到了'http://www.baidu.',这表明了+的贪婪,尽可能多的匹配,通过加上一个?,变成了懒惰的 text7 = r"http://www.baidu.com/" p7 = r"http.+\." pat7 = re.compile(p7) print("7:", pat7.findall(text7)) p8 = r"http.+?\." pat8 = re.compile(p8) print("8:", pat8.findall(text7)) #精准控制匹配次数{a,b},匹配次数大于等于a,小于等于b text9 = r"python pyython pyyython pyyyython pyyyyython" p9 = r"py{1,2}thon" pat9 = re.compile(p9) print("9:", pat9.findall(text9)) p10 = r"py{4,5}thon" pat10 = re.compile(p10) print("10:", pat10.findall(text9))