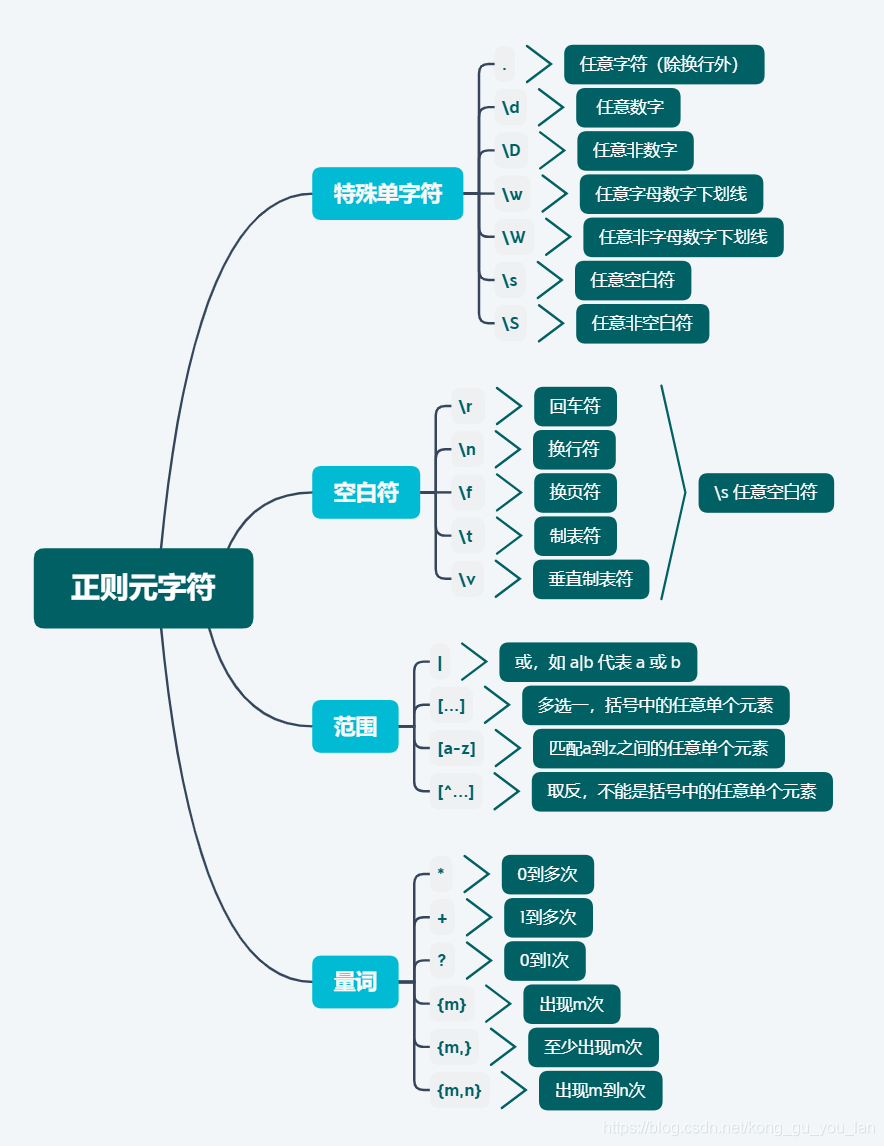
这是一个初秋的夜晚,天气晴朗,一丝风都没有,抬头仰望,湛蓝的天空中,挂着一轮金黄的圆月。月亮把它那淡淡的月光毫不吝啬地撒向洞庭湖。圆月四周,稀稀疏疏地点缀着几颗星星,那几颗星星也把微弱的光源聚集起来,撒向月光下的湖面。这下,洞庭湖真是美极了。
先来看下问题。 字符串
$str = '<script>123456</script>';
正则表达式为
$strRegex1 = '%<script>.+<\/script>%';
$strRegex2 = '%<script>.+?<\/script>%';
$strRegex3 = '%<script>(?:(?!<\/script>).)+<\/script>%';
这三个正则,分别会造成几次回溯呢??
答案:
$strRegex1 = '%<script>.+<\/script>%'; //9次,记得区别转义符号。
$strRegex2 = '%<script>.+?<\/script>%'; //5次
$strRegex3 = '%<script>(?:(?!<\/script>).)+<\/script>%'; //7次
对于第一种贪婪匹配的匹配规则,回溯的9次是正则【】对字符串“”匹配时,构成的回溯,回溯的次数,恰好是字符串的长度。
第二种非贪婪匹配规则,回溯5次,是正则【.+?】对字符串“123456”匹配时构成的回溯。回溯的次数,为字符串长度减去最小次数。也就是6-1=5次。如果正则表达式为【.*?】那么,回溯次数就是6次了。
第三种正则是零宽断言,或者叫环视。(暂且不说。)
在NFA正则引擎中,回溯是他的灵魂,所以,不管是贪婪,非贪婪,环视等写法中肯定会有回溯的出现的,这个我们无法避免(用词不太准确),但是,我们可以减少回溯的次数,或者保护其中一部分匹配的规则不进行回溯。 对于上篇BLOG上提到的鸟哥谈到一个非贪婪引起的大量回溯问题,大家可以知道,回溯,确实是浪费资源的罪魁祸首,那么,我们能否不让其回溯呢?
答案是肯定的,NFA引擎中,有个概念,叫固化分组。引用一下书上的概念
具体来说,使用「(?>…)」的匹配与正常的匹配并无差别,但是如果匹配进行到此结构之后(也就是,进行到闭括号之后),那么此结构体中的所有备用状态都会被放弃。也就是说,在固化分组匹配结束时,它已经匹配的文本已经固化为一个单元,只能作为整体而保留或放弃。括号内的子表达式中未尝试过的备用状态都不复存在了,所以回溯永远也不能选择其中的状态(至少是,当此结构匹配完成时,“锁定(locked in)”在其中的状态)。
那么,固化分组到底有什么用处呢?我们来举个例子。(找不到合适的例子,俺只好借用一下书上的例子了)
比如要处理一批数据,原来格式为123.456,后来因为浮点数显示问题,部分数据格式变为123.456000000789这种,,要求做到只保留小数点后面2-3位,但是,最后一位不能为0,这个正则如何写呢?(下面直接考虑小数点后面的数字),写出正则之后,我们还要用这个正则去匹配数据,把原来的数据替换成匹配的结果。
首先,我们可以立刻写出这样的正则【\.\d\d[1-9]?\d*】,PHP代码为
$str = preg_replace('\.(\d\d[1-9]?)\d*','\\1',$str); //匹配结果的group1进行反向引用
很明显,这种写法,对于部分数据格式为123.456的这种格式,白白的处理了一遍,为了提高效率,我们还要对这个正则进行处理。从123.456这个字符串跟其他的比较一下,我们发现,是疑问123.456这个数据后面没数字了,所以,白白处理一遍。那好办,我们对这个正则改造一下,把后面的量词*改成+,这样对于123.45 小数点后面1,2位数字的,不会去白白处理,而且,对三位以上数字的,处理正常。其PHP代码为
$str = preg_replace('\.(\d\d[1-9]?)\d+','\\1',$str);
好了,这个正则真的没问题吗??确定吗?上篇博文,我们了解了匹配原理,那么,我们也分析一下这个正则的匹配过程吧。
字符串"123.456",正则表达式为【\.(\d\d[1-9]?)\d+】,我们来看下
首先(小数点前123不说了),【\.】匹配".",匹配成功,把控制权给下一个【\d】,【\d】匹配“4”成功,把控制权给第二个【\d】,这个【\d】匹配“5”成功,然后,把控制权给了【[1-9]?】,由于量词是【?】,正则表达式遵循“量词优先匹配”,而且,此处是【?】,还会留下一个回溯点。然后匹配"6"成功,然后把控制权给【\d+】,【\d+】发现后面没字符了,最遵循“后进先出”规则,回到上一个回溯点,进行匹配,这时,【[1-9]?】会交还出其匹配的字符“6”,【[1-9]?】匹配“6”成功。匹配完成了。大家发现【(\d\d[1-9]?)】匹配的结果确是"45",并不是我们想要的“456”,“6”被【\d+】匹配去了。那么,我们该如何办呢? 能否让【[1-9]?】匹配一旦成功,不进行回溯呢?这就用到了我们上面说的"固化分组", PHP(preg_replace函数)中使用的正则引擎支持固化分组,我们根据固化分组的写法,可以把代码改成如下方式
$str = preg_replace('\.(\d\d(?>[1-9]?))\d+','\\1',$str);
改成这样的话,那字符串“123.456“是不符合要求,不会被匹配的。那我们就可以实现我们的要求了。 从上面的例子中,知道了固化分组的作用,那么对于鸟哥BLOG上写的那个非贪婪的回溯问题,我们能否也对其改造,使得其不回溯呢?
先看下鸟哥给的答案
/<script>[^<]*<\/script>/is
鸟哥写的很精悍。排除“<”之外的所有字符都符合,而且,中间部分不回溯,效率高。可是,如果中间有字符“<“的话(如下代码)
<script>
if a < b
</script>
那鸟哥的这个正则就不能匹配,就不能实现我们想要的功能了。
那我们可以根据 固化分组、环视(零宽断言)来实现这个要求,最后,CFC4N给出的正则以及PHP代码事例如下
$reg = '%<script>(?>[^<]*)(?>(?!</?script>)<[^<]*)*</script>%is';
$str = str_pad("<script>", 111111, "*"); //字符长度大于PHP回溯限制的100000
$str .= 'if a < b ; if b > c;</script>'; //随便加几个包含 < > 的测试字符
$ret = preg_replace($reg, "OK", $str);
print_r($ret); //打印结果 OK,证明匹配正确
var_dump(preg_last_error()); //上一次匹配错误。其输出为 int(0)
嗨,同学,你看明白了吗? 以上为小菜CFC4N的愚文,如有错误,欢迎指出。
本文PHP正则表达式的效率 回溯与固化分组到此结束。把热爱的事情做到极致,便成了价值。小编再次感谢大家对我们的支持!