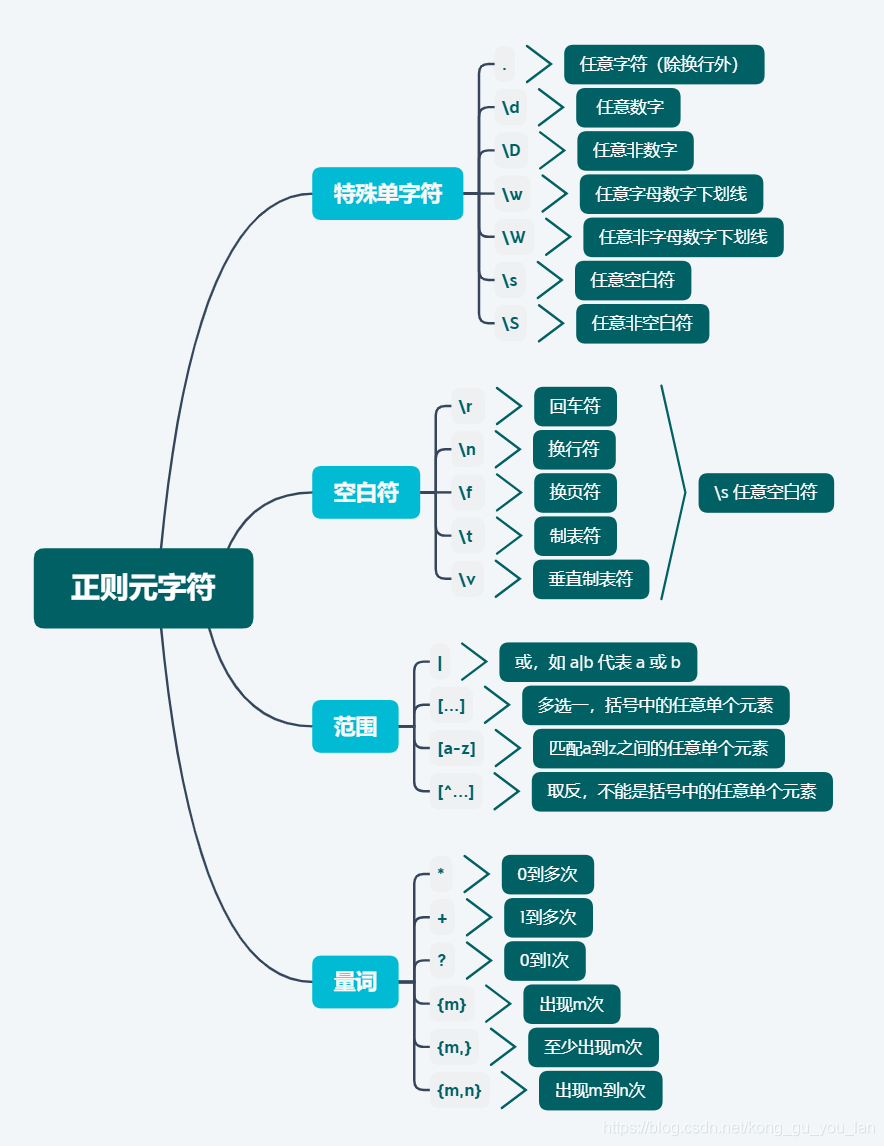
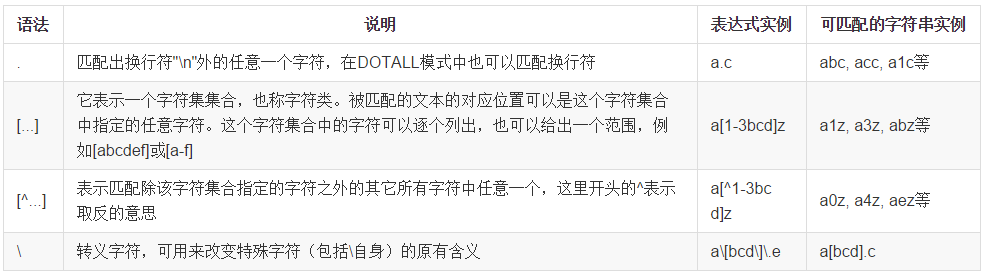
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,包括普通字符(例如,a 到

正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符"),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。
在 Linux 中,正则表达式是一种强大的文本匹配工具,它允许您按照某种模式来搜索、匹配和处理文本。正则表达式通常用于命令行工具如 grep、sed、awk 以及编程语言如 Python、Perl 和 JavaScript 中。
以下是如何在 Linux 中使用正则表达式的一些基本示例:
字符类:使用方括号 [ ] 来匹配字符集中的一个字符。例如,[aeiou] 匹配任何一个元音字母。
grep "[aeiou]" 文件名通配符:使用 . 来匹配任何单个字符,* 匹配前一个字符的零个或多个重复。
grep "a.ple" 文件名 # 匹配 "apple"、"ample" 等 grep "apple" 文件名 # 匹配 "pple"、"appple" 等
范围:使用 - 来指定字符范围,例如 [0-9] 匹配任何数字。
grep "[0-9]" 文件名 # 匹配包含数字的行 grep -E "2023-09-07 (09:[4-5][0-9]|10:[0-5][0-9])" #匹配日期为 2023-09-07 且时间在 09:40 到 10:59 之间的
重复次数:使用 { } 来指定重复次数。
grep "a{2,4}" 文件名 # 匹配 "aa"、"aaa" 和 "aaaa",但不匹配 "a" 或 "aaaaa"
特殊字符转义:某些字符在正则表达式中具有特殊含义,如果要匹配这些字符本身,需要使用 进行转义。
grep "." 文件名 # 匹配句点字符 "."
锚点:使用 ^ 来匹配行的开头,使用 $ 来匹配行的结尾。
grep "^apple" 文件名 # 匹配以 "apple" 开头的行 grep "apple$" 文件名 # 匹配以 "apple" 结尾的行
逻辑操作:使用 | 表示或运算,可以将多个模式组合在一起。
grep "apple|banana" 文件名 # 匹配包含 "apple" 或 "banana" 的行