Linux Shell脚本之正则表达式
一、常见的管道命令
sort命令
sort命令可针对文本文件的内容,以行为单位来排序
格式:sort [选项] 参数
常用选项
选项 说明
-f 忽略大小写,会将小写字母都转换为大写字母来进行比较
-b 忽略每行前面的空格
-n 按照数字进行排序
-r 反向排序
-u 等同于uniq,表示相同的数据仅显示一行
-t 指定字段分隔符,默认使用[Tab]键分隔
-k 指定排序字段
-o <输出文件> 将排序后的结果转存至指定文件
uniq命令
uniq 命令用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用
格式:uniq [选项] 参数
常用选项
选项 说明
-c 进行计数,并删除文件中重复出现的行
-d 仅显示连续的重复行
-u 仅显示出现一次的行
tr命令
常用来对来自标准输入的字符进行替换、压缩和删除
格式:tr [选项] [参数]
常用选项
选项 说明
-c 保留字符集1的字符,其他的字符用(包括换行符\n)字符集2替换
-d 删除所有属于字符集1的字符
-s 将重复出现的字符串压缩为一个字符串;用字符集2 替换 字符集1
-t 字符集2 替换 字符集1,不加选项同结果
常用参数
参数 说明
字符集1:指定要转换或删除的原字符集。当执行转换操作时,必须使用参数“字符集2”指定转换的目标字符集。但执行删除操作时,不需要参数“字符集2”
字符集2:指定要转换成的目标
cut命令
显示行中的指定部分,删除文件中指定字段
格式:cut [选项] 参数
常用选项
选项 说明
-f 通过指定哪一个字段进行提取。cut命令使用“TAB”作为默认的字段分割符
-d “TAB”是默认的分隔符,使用此选项可更改为其他的分隔符
- -complement 用于排除所指定的字段
- -output-delimiter 更改输出内容的分隔符
例:统计当前连接主机数

二、正则表达式
正则表达式的定义
正则表达式,又称正规表达式、常规表达式
使用字符串来描述、匹配一系列符合某个规则的字符串
正则表达式组成
普通字符包括大小写字母、数字、标点符号及一些其他符号
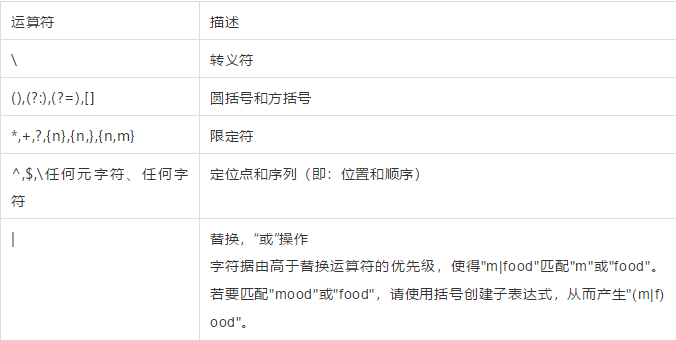
元字符是指在正则表达式中具有特殊意义的专用字符
常见元字符
支持的工具:find、grep、egrep、sed和awk
匹配符 表示含义
. 表示任意一个字符
[ ] 匹配括号中的一个字符
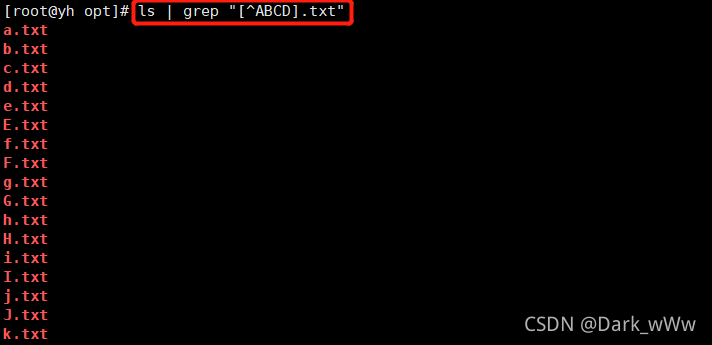
[^ ] 表示否定括号中出现字符类中的字符,取反
\转义字符 用于取消特殊符号的含义
^ 匹配字符串开始的位置
$ 匹配字符串结束的位置
{n} 匹配前面的子表达式n次
{n,} 匹配前面的子表达式不少于n次
{n,m} 匹配前面的子表达式n到m次
[:alnum:] 匹配任意字母和数字
[:alpha:] 匹配任意字母,大写或小写
[:lower:] 小写字符a-z
[:upper:] 大写字符A-Z
[:blank:] 空格和TAB字符
[:space:] 所有空白字符( 新行、空格、制表符)
[:digit:] 数字 0-9
[:xdigit:] 16 进制数字
[:cntrl:] 控制字符
例:表示一个任意字符

例:[ ] 匹配括号中的一个字符


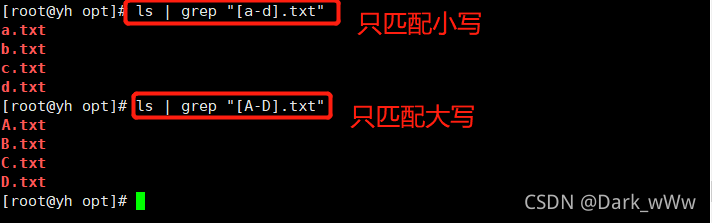
例:[^] 表示否定括号出现字符类中的字符,取反
例:[:alnum:] 匹配任意字母和数字
一定要在外面再套一个[ ]

例:元字符 (.)

三、扩展正则表达式
支持的工具:egrep、awk 或 grep -E 和 sed -r
限定符 说明
* 匹配前面子表达式0次或者多次
.* 任意长度的任意字符
? 匹配前面子表达式0次或者1次,即:可有可无
+ 与星号相似,表示其前面字符出现一次或多次,但必须出现一次,>=1
{n,m} 匹配前面的子表达式n到m次
{m} 匹配前面的子表达式n次
{n,} 匹配前面的子表达式不少于n次 >=n
{,n} 匹配前面的子表达式最多n次,<=n
| 用逻辑OR(或)方式指定正则表达式要是用的模式
() 字符串分组,将括号中的字符串作为一个整体
例:* 匹配前面子表达式 0 此或者多次

例:{n,m} 匹配前面的子表达式 n 到 m 次

例:{n,} 匹配前面的子表达式不少于n次>=n

例:{,n} 匹配前面的子表达式最多n次,<=n

例:* 任意长度的任意字符

例:? 匹配前面表达式0次或者1次,即:可有可无

例:+ 与星号相似,表示其前面字符出现一次或多次,但必须出现一次, >=1

例:| 逻辑 or (或)方式指定正则表达式要是用的模式

例:()字符串分组,将括号中的字符串作为一个整体

例:提取IP地址
法一:

法二:

位置锚定
位置限定符 说明
^ 行首锚定,用于模式的最左侧
$ 行尾锚定,用于模式的最右侧
^PATTERN^ 用于模式匹配整行
^$ 空行
^[[:space:]]*$ 空白行
\< 或 \b 词首锚定,用于单词模式的左侧(连续的数字,字母下划线都算)
\>或 \b 词尾锚定,用于单词的右侧
\<PATTERN\> 匹配整个单词
例:行尾锚定,用于模式的最右侧

例:行首锚定,用于模式的最左侧

例:用于模式匹配整行,匹配的内容单独在一行

例:\< 只匹配右侧的单词

例:\> 只匹配左侧的单词

例:过滤出不是以#开头的非空行